
The law of large numbers is one of the most important theorems in probability theory. It states that, as a probabilistic process is repeated a large number of times, the relative frequencies of its possible outcomes will get closer and closer to their respective probabilities.
For example, flipping a regular coin many times results in approximately 50% heads and 50% tails frequency, since the probabilities of those outcomes are both 0.5.
The law of large numbers demonstrates and proves the fundamental relationship between the concepts of probability and frequency. In a way, it provides the bridge between probability theory and the real world.
In this post I’m going to introduce the law with a few examples. I’m going to skip the formal proof, as it requires a slightly more advanced mathematical machinery. But even the informal proof I’m going to show you should give a good intuition for why the law works.
Table of Contents
Introduction
First, let’s define the relative frequency of any of the possible outcomes of a random process. It is the number of times the outcome has happened divided by the total number of trials. In other words, it’s the percentage of trials in which the outcome has occurred.
Let’s say you flip a regular coin a certain number of times. After each flip you record if it was heads or tails. At the end you calculate the total count of the 2 outcomes. Here’s a question for you. About what % of the the flips do you think will be heads?
Your gut feeling is to say “about 50%”, yes? That’s because you know regular coins have about 0.5 probability of landing heads. Your reasoning is correct, but still, let’s try to apply some skepticism.
I said you flipped the coin a certain number of times but I didn’t say how many. What if you only flip it once? Then, if it lands heads, 100% of the flips will be heads, otherwise 0% will be heads. Those are clearly not the expected 50%!
What if you flip it, say, 4 times? Well, grab a coin and try this experiment on your own. You’ll see that it’s not that uncommon to get sequences with 3 or even 4 heads/tails. In such cases, you will still get relative frequencies like 0%, 25%, and 75%. As you can see, the “about 50%” answer is at least a little suspicious.
Of course, when I said that you flip the coin “a certain number of times”, you probably assumed I meant a higher number, like 100 or 1000. Then, you say, the relative frequency of heads flips will be much closer to 50%. And I agree.
In fact, this is exactly what the law of large numbers is all about.
The law of large numbers
When you flip the coin 1, 2, 4, 10, etc. times, the relative frequency of heads can easily happen to be away from the expected 50%. That’s because 1, 2, 4, 10… are all small numbers. On the other hand, if you flip the coin 1000 or 10000000 times, then the relative frequency will be very close to 50%, since 1000 and 10000000 are large numbers.
Before I continue, let’s get some visual intuition about this. I wrote a short code to simulate 1000 random coin flips and plotted the % of heads after each flip. Click on the image below to see the animated simulation:
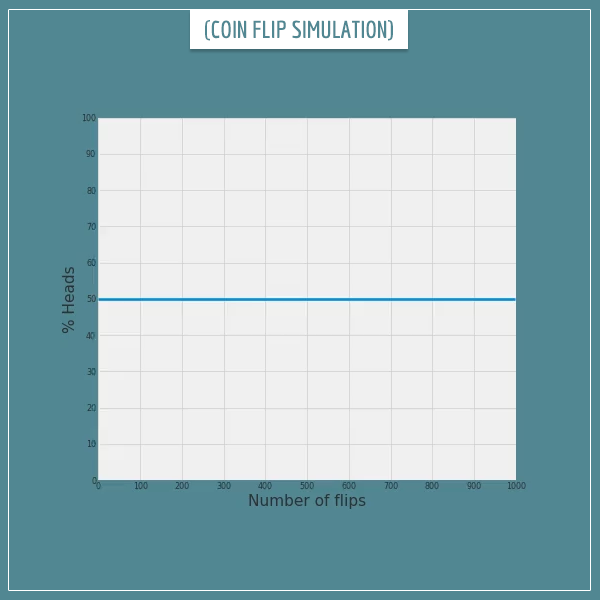 Click on the image to start/restart the animation.
Click on the image to start/restart the animation.
As you can see, when the number of flips (let’s call it N) is small, the relative frequency can be quite unpredictable. It starts at 0 because the first flip happened to be tails. Then it sharply jumps to values above 50% and eventually, around the 500th flip, it starts to settle around the expected 50%. So, notice that even N = 200 is still not “large enough” for the relative frequency to get “close enough” to the probability.
At this point you might be asking yourself a natural question. As far as the law of large numbers is concerned, what exactly is considered a high N? The answer is that there isn’t a magical number that is always large enough for any random process. Some might require a higher or lower number of repetitions for the relative frequency of the outcomes to start converging to their respective probabilities. I will come back to this point later.
By the way, those of you who read my post on estimating coin bias with Bayes’ theorem might make an interesting connection. As a small exercise, I’ll let you think about how the law of large numbers relates to the shape of the posterior distribution of a coin’s bias parameter as the number of flips increases. Also think about the general connection with parameter estimation, which I talked about in the Bayesian vs. Frequentist post. Don’t hesitate to share your thoughts in the comment section below!
In the next section, I’m going to show a few more examples. Then I’m going to state the law in a bit more formal mathematical terms and show you an intuitive proof for why it works.
More examples
Let’s take a look at another animated simulation of 1000 flips of the same coin.
Click on the image to start/restart the animation.
This time the first flip happened to be heads, that’s why the frequency starts all the way at 100%. Notice that the convergence is slightly slower compared to the previous simulation. In fact, even after 1000 flips, it hasn’t quite settled around 50%. Further evidence that there isn’t a special number of flips that will guarantee a “good enough” convergence.
Now let’s look at another simulation of 1000 flips. But this time we’re flipping a fake coin that has a 0.65 bias towards heads. Meaning, the probability of landing heads is 0.65, instead of 0.5. Here’s the results from the code I just ran:
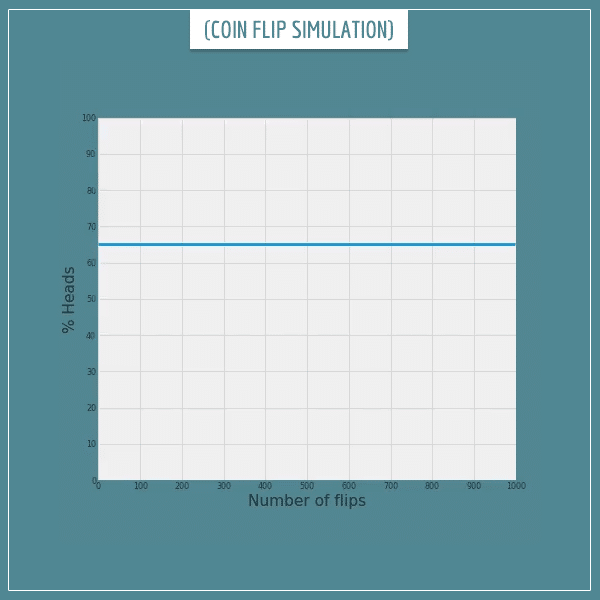 Click on the image to start/restart the animation.
Click on the image to start/restart the animation.
Again, no problem, the frequency converges towards the probability at a similar rate as in the previous examples..
Notice that in each case the exact path of convergence is quite unique and unpredictable. In a way, this makes the law of large numbers beautiful. Regardless of how exactly the long-term frequency reaches the theoretical probability, the law guarantees that sooner or later the two will meet.
Now let’s look at a slightly more complicated random process than flipping a coin. Instead, let’s roll some dice.
After a single roll of a die, any of the six sides has an equal probability of 1/6 to be on top. This means that, according to the law of large numbers, the expected long-term frequency of each side should be ~16.7%. Take a look:
 Click on the image to start/restart the animation.
Click on the image to start/restart the animation.
Again, notice that even after hundreds of rolls, the relative frequencies haven’t completely settled towards the expected ones. In fact, it seems like convergence here is somewhat slower compared to the coin flipping example, doesn’t it? It will generally take longer for relative frequencies of a process with six possible outcomes to settle, compared to a process with only two possible outcomes. I’ll come back to this point in a bit.
Take a look at what path the frequency of each outcome took in the simulation (the black dashed line indicates the expected percentage (EP)):
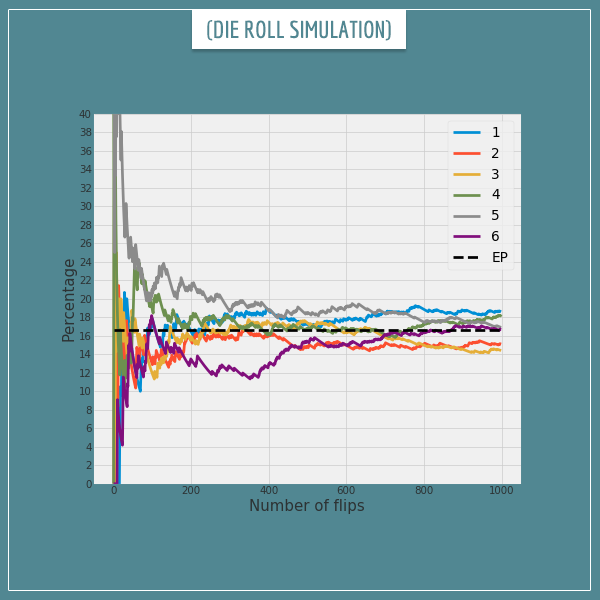
You can see deviations from the EP as large as 5% even after 100-200 rolls. In fact, even at the end of 1000 rolls, most sides’ relative frequencies have not completely converged. Think about the kinds of implications this could have if you decide to play some sort of a gambling game involving rolling dice!
A formal statement of the law of large numbers

The law of large numbers was something mathematicians were aware of even around the 16th century. But it was first formally proved in the beginning of the 18th century, with significant refinements by other mathematicians throughout the following 2-3 centuries.
So far, I’ve been implicitly using a particular form of the law stated by the 20th century French mathematician Émile Borel.
In words, this formulation says that when the same random process is repeated a large number of times, the relative frequency of the possible outcomes will be approximately equal to their respective probabilities.
Here’s the same statement, formulated as a mathematical limit (don’t worry if you’re not familiar with limits, I’ll explain what each of the terms means):
 Here n is the number of times the random process was repeated.
Here n is the number of times the random process was repeated.
Nn(outcome) is the number of times a particular outcome has occurred after n repetitions.
P(outcome) is the probability of the outcome.
The arrows are standard notation when writing limits and should be read as “approaches”.
The ∞ symbol represent (positive) infinity.
For any given n, Nn(outcome)/n is equal to the relative frequency of that outcome after n repetitions.
Here’s how the statement above reads:
- Nn(outcome)/n approaches P(outcome), as n approaches infinity.
For one value to approach another simply means to get closer and closer to it. So, a more verbose way to read the statement would be:
- The relative frequency of an outcome after n repetitions gets closer to its probability, as n gets closer and closer to infinity.
Of course, for a number to get closer to infinity simply means that it keeps getting larger and larger.
The law of large numbers is both intuitive and easy to formulate. I also showed you some empirical evidence for its validity. But does it really always work?
Just because it works for random processes like flipping a coin and rolling a die, does it mean it will work for any random process? Not to mention that those weren’t even the “real” processes, but computer simulations of them.
You’re right, you can’t just blindly accept something as true, just because it sounds intuitive. Especially in mathematics. And even less so in probability theory!
Fortunately, formal proofs do exist. Some forms of the law are called weak, where only “convergence in probability” is guaranteed, as opposed to stronger formulations of the law, where “almost sure” convergence is guaranteed.
I won’t go into detail about those distinctions here, as it would require slightly more advanced concepts beyond the scope of this post. If you’re curious about the terms, feel free to check out the Almost surely and almost never section of my post on the meaning of zero probabilities.
An informal proof of the law of large numbers
First, let’s establish what conditions about the random process need to be true for the law to hold.
The part of the law which says that “the same random process” needs to be repeated a large number of times means that the process is repeated under identical conditions and the probability of each outcome is independent of any of the previous outcomes. In probability theory, this is known as being independent and identically distributed (IID).
If probabilistic dependence is a new concept to you, check out the Event (in)dependence section of my post about compound event probabilities.
Anyway, back to the proof.
A toy example with fake coins
 Imagine you have these special coins where both sides of the coin are the same (either both are heads or both are tails). Say you have exactly 50 of the “heads” coins and 50 of the “tails” coins. You put all N = 100 coins in a bag and mix it really well.
Imagine you have these special coins where both sides of the coin are the same (either both are heads or both are tails). Say you have exactly 50 of the “heads” coins and 50 of the “tails” coins. You put all N = 100 coins in a bag and mix it really well.
Now you close your eyes and draw n number of those coins and calculate the % of them that were heads. This should be familiar territory by now. If n = 1, the % will be 0 or 100, depending on the kind of coin you happened to draw.
What if n = 99? Now you have drawn all but 1 of the coins. If the one remaining coin is a “heads” coin, the proportion of heads among the drawn coins will be 49/99, which is about 49.5%. On the other hand, if the remaining coin is “tails”, the proportion will be 50/99, or approximately 50.5%. In both cases, the % is very close to the actual 50% of “heads” coins in the bag.
What if we make n = 98? Here, the worst possible deviation from 50% would happen if the 2 remaining coins were of the same kind. In those cases, the % of heads would be 48/98 ≈ 49% or 50/98 ≈ 51%.
 The point I’m trying to make is that, when n is very close to N (in this case 100), even in the worst case scenario you still get a relative frequency very close to the real one (50%). But if you keep decreasing n, as you get closer to 0, the % of heads can have very large deviations from 50% (for example, when n < 10). And, of course, when n = N (100 coins drawn), the % of heads will be exactly equal to 50.
The point I’m trying to make is that, when n is very close to N (in this case 100), even in the worst case scenario you still get a relative frequency very close to the real one (50%). But if you keep decreasing n, as you get closer to 0, the % of heads can have very large deviations from 50% (for example, when n < 10). And, of course, when n = N (100 coins drawn), the % of heads will be exactly equal to 50.
Generalizing to the infinite case
Now imagine the exact same example as the one above but with one difference. Every time you draw a coin from the bag, instead of putting it aside, you just write down its type, throw it back inside, and reshuffle the bag.
By following this procedure, we are essentially creating the identical and independent conditions required by the law of large numbers. Because we shuffle the bag after each draw, we are guaranteeing the same 0.5 probability of drawing either kind on every trial. This follows from the classical definition of probability I introduced in a previous post.
 If you think about it, this example is basically equivalent to flipping a regular coin n number of times. In both cases, trials are independent of each other and in both cases there are 2 possible outcomes, each with a probability of 0.5.
If you think about it, this example is basically equivalent to flipping a regular coin n number of times. In both cases, trials are independent of each other and in both cases there are 2 possible outcomes, each with a probability of 0.5.
If you stretch your imagination a little bit, the example is also equivalent to a hypothetical situation where you have a magical bag with an infinite number of coins, where “half” of them are “heads” coins and the other “half” are “tails” coins. In other words, this is just like the toy example above, but instead of N = 100, we have… N = ∞.
When all 100 coins in the toy example are drawn, the frequency of the outcomes exactly matches the frequency of each type of coin in the bag. But when N is infinity, what exactly does it mean to have drawn all coins? Well, it just means to draw a lot of coins!
*Drum rolls*…
When n = N, the frequency of an outcome is equal to its probability. Therefore, when N = ∞, the frequency of an outcome will become equal to its probability when n = ∞.
In other words, with the toy example (where N was a finite number) we established that as n gets closer to N, it becomes harder and harder for the relative frequency to deviate too much from the expected relative frequency. And now you just need to transfer this intuition to the case where N is infinity.
Like I said, this is not a formal proof. It’s something intended to give you a general intuition for why the law of large numbers works. If you find any of this confusing, feel free to ask questions in the comment section.
How large is large enough?
The last thing I want to briefly touch upon is something that came up several times throughout this post. Namely, how many trials does it take for the law of large numbers to start “working”?
The short answer is that the question itself is a bit vague. Remember, the law of large numbers guarantees that the empirical relative frequency of an outcome will be approaching (getting closer to) its expected relative frequency (as determined by the probability of the outcome). So, a piece of information that needs to be added to the above question is how close do you need to get to the expected frequency.
For example, when flipping a coin, if you might not mind a difference of, say 5%. In that case, even a few hundred flips will get you there. On the other hand, if you need to rely on a relative frequency that is almost equal to the expected 50%, you will need a higher number of flips. Like the law says, the higher the number of trials, the closer the relative frequency will be to the expected one.
Another important factor is variance. Generally, the higher number of possible outcomes a random process has and the closer the outcomes are to being equiprobable, the longer it will take for the relative frequencies to converge to their respective probabilities. You already saw this with the die rolling example. After 1000 rolls, convergence was worse compared to the earlier coin examples (again after 1000 flips).
There are mathematical papers that go deeper into this topic and give formal estimates for the rate of convergence under different conditions. But I think by now you should have a good initial intuition about it. The best way to get a better feel is to play around with other simulations. Maybe more complicated than flipping coins and rolling dice. Try to see the kinds of factors that determine the rate of convergence for yourself.
Summary
In this post, I introduced the law of large numbers with a few examples and a formal definition. I also showed a less formal proof. Here’s a few take-home points.
The law of large numbers shows the inherent relationship between relative frequency and probability. In a way, it is what makes probabilities useful. It essentially allows people to make predictions about real-world events based on them.
The law is called the law of large numbers for a reason — it doesn’t “work” with small numbers. But what is a large number depends very much on the context. The closer you need to get to the expected frequency, the larger number of trials you will need. Also, more complex random processes which have a higher number of possible outcomes will require a higher number of trials as well.
The law of large numbers is a mathematical theorem but it’s probably not an incident that it actually has the word ‘law’ in it. I like to think about it in similar terms as some natural physical laws, such as gravitation. The probability of an outcome is like a large body that “pulls” the empirical frequency towards itself! The exact trajectory might be different every time, but sooner or later it will reach it. Just like a paper plane thrown from the top of a building will eventually reach the ground.
I hope you found this post useful. And if you did, you will likely find my post about the concept of expected value interesting too.
In future posts, I will talk about the more general concept of convergence of random variables, where convergence works even if some of the IID requirements of the law of large numbers are violated.
See you in soon!
Very good. But can you explain the life-changing FDA trials that rely on n as small as 10 in a control and 20 overall? FDA has just approved a trial for Invivo Therapeutics that is for spinal cord paralysis. There has to be a 20% difference in measurable recovery between the two sample groups to satisfy the trial. How does this make sense? Is it valid? How is a n=10 sample for a control better than using existing data from the universe of patients historically available?
Hi, Ken. That’s an excellent question. I’m glad I have an opportunity to compare these 2 general cases.
In the context of the law of large numbers (LLN), we’re interested in estimating the probability P of an outcome by its frequency over some number of trials. Here, how large n should be will depend on how close we want our estimate to be to the real value, as well as on the size of P. Smaller P’s will generally require larger n’s to get a good estimate.
The n in the types of studies you mentioned has different requirements to satisfy. I haven’t read the specific study you described, but my guess is they are comparing some central measure (like the mean) between a control group and the experimental group using the therapeutics and testing the difference for statistical significance.
When dealing with null hypothesis significance testing (NHST) and p-values, you’re trying to avoid making one of the two types of statistical error and you need some adequate n for that. And you’re concerned about stuff like statistical power. But like I said, what is adequate for this domain depends on different things compared to the situation with the LLN.
If you want to learn more about the things I just described, you can check out my post explaining p-values and NHST.
Now, having said all that, n=10 does sound like a very small number for such a study (or any study really, but especially for a study of such importance). Unfortunately, a lot of studies in social sciences do suffer from significant methodological weaknesses, so your suspicions about that particular study are most likely justified.
As for your question about historical patient data, I couldn’t agree more. In my opinion, one of the significant downsides of NHST is precisely the fact that it forces every study to be conducted in a sort of “scientific vacuum”, without the ability to incorporate already existing data into the analysis.
To summarize my answer, in NHST you can get away with smaller n because you’re not concerned with exact estimation of any parameters but simply with wanting to make sure that two means aren’t equal to each other (or that the effect size is larger than some threshold, which is related to the 20% required difference you mentioned). But despite that, for this particular case your concerns are most likely quite valid.
Edward Thorp: “The main disadvantage to buy-and-hold versus indexing is the added risk. In gambling terms, the return to buy-and-hold is like that from buying the index then adding random gains or losses by repeatedly flipping a coin. However, with a holding of 20 or so stocks spread out over different industries, this extra risk tends to be small”.
Is Thorp referring to the law of large numbers? Thanks so much.
Hey Bing.
Thorp is talking about the added variance on your expected return on investment when you choose to do by-and-hold, compared to if you’re just buying the index. He isn’t directly talking about the law of large numbers, but the truth of his claim does implicitly depend on it. Well, any time you’re investing and there’s any kind of risk involved (this probably covers close to 100% of all investments), you are relying on the law of large numbers to turn a profit in the long run, even if you do end up suffering temporary losses from individual investments.
Does this help?
One of the best explanations I’ve come across!
I have a question about the LLN, or rather the flipside of the LLN. It needs a bit of an introduction.
In a game show, the participant is allowed to choose one of three doors: behind one door there is a prize, the other two doors get you nothing. After the participant has chosen a door, the host will stand before another door, indicating that that door does not lead to the prize. He then gives the participant the option to stick with his initial choice, or switch to the third door.
The question is then, should the participant switch or stay with his original choice. Most people intuitively answer that it doesn’t matter; it’s fifty/fifty. Statistically, however, it does matter (as you will no doubt have immediately perceived) as the probability of winning is larger if you switch. If your initial choice is one of the two wrong doors (probability two out of three), switching will win you the prize, while if you choose the right door initially (probability only one out of three), will switching make you lose.
So far so good. Now the intuitive inference made by many people is, that if you play this game, you should always switch as that increases the probability of you winning the prize.
Now this, I think, does not necesarrily make sense as it does not take into account the law of large numbers. As I understand it, probabiltiy only has real world predictive meaning if N is sufficiently high. And even then, probability only has predictive value as to the likelyhood of an outcome occurring a certain number of times but not as to the likelyhood of an outcome in one individual case. In other words, the fact that the probablity of getting tails is 50 % mathematically, and will approach 50 % after a thousand flips, tells me nothing about the likely outcome of flip number 446.
So my conclusion would then be that the people who believe that switching doors in the game show example doesn’t make any difference, are in fact right (although perhaps not always thanks to the right reasoning). But at lunch today I seemed to be unable to convince anyone of this. So please tell me whether I am way off base.
Thank you.
Hi, Hugo! Thanks for the question. You are talking, of course, about the famous Monty Hall problem which is one of the interesting (and counter-intuitive) problems with probabilities.
Well, this way of thinking would be a rather extreme version of a frequentist philosophy to probabilities. Are you familiar with the different philosophical approaches to probability? If not, please check out my post on the topic. I think it will address exactly the kind of questions you have about how to interpret probabilities.
But let me clarify something important. Probabilities do have meaning even for single trials. It is true that you can never be completely certain about individual outcomes of a random variable. However, you can still have higher/lower expectations about individual outcomes, depending on the probability.
Imagine a version of the Monty Hall problem where instead of 3 doors, there’s a million of them (again, only one of them has a reward). Then once you choose your door and the host opens 999 998 of the remaining doors without reward, would you still be indifferent between switching from your initial choice? My strong guess would be that in a real life situation you would always switch doors, regardless of how many times you’re allowed to play the game.
Does that make sense?
Here’s an even more straightforward way of demonstrating this. Say there’s a box with 2 red balls and 1 green ball. You bet some amount of money on correctly guessing the color of the ball that is going to be randomly drawn from the box. If you guess right, you double your money, else you lose your bet. Wouldn’t you always choose to bet on a red color? And if yes, then shouldn’t you also always choose to switch doors in the Monty Hall problem?
By the way, a few months ago I received a similar question in a Facebook comment under the link for this post. Please do check out the discussion there.
Let me know if you find my explanation convincing.
Thank you for your reply!
Am I convinced?
Mmmmmmh.
My reasoning is this. I am no mathematician but I suppose that If “N(outcome)/N -> P(outcome) as N-> infinity” is true, than my the question is
N(outcome)/N (what?) P(outcome) as N->0.
In other words, what does the LLN tell us about the case where N is a small number (for example 1).
Let’s take your two green ball and one red ball example and add another choice. You have one million Dollars to bet with. You can choose to gamble once and go all in, or you can choose to bet one thousand times a thousand dollars. The second strategy provides excellent odds for a profit of around 330 thousand dollars. You can win a lot more going all in, but there is a real chance of losing everything.
Spreading your bets means you are using probability and the LLN to your advantage as you are,as it were, crossing the bridge between probability theory and the real world.
So we can safely say that making a decision based on theoretical probability is more realistic (and useful) as N -> infinity and less useful as N-> 0.
Now your million door Monty Hall example is, of course, an example of an extremely loaded coin. The heads side is flat and made of lead and the tails side is pointed and made of styrofoam. So yes, of course, you chose tails. That being said, if the coin is that biased (a million to one), it does something to the coin flip simulation. In that case P is so closed to 0 % that frequency convergence happens practically immediately (probabiltiy as a propensity).
So there seems to be a connection between bias and the rate of frequency convergence.
The conclusion of all this would be that using probability to make a decision (e.g. switch or stay) depends on (a) the amount of times you get to try again and (b) the initial bias.
Back to the original Monty Hall problem. You get to try only once. That is as low as N can get. The bias is there but still can be expected to diverge before settling down on the P-axis.
So yes intuitvely you might still make the “best bet” and switch but realistically, you are just as well off attempting to smell the goat.
On the other hand, maybe I should just take a maths course.
“In other words, what does the LLN tell us about the case where N is a small number (for example 1).”
Well, nothing. It doesn’t even try, however, as it is a law for large numbers only 🙂 More specifically, infinitely large numbers.
But like I said, probabilities have their own existence, independent of the LLN. They are measures of expectations for single trials. In a way, the law of large numbers operationalizes this expectation for situations where a trial can be repeated an arbitrary number of times. It is a theorem that relates two otherwise distinct concepts: probabilities and frequencies.
You are absolutely right though – smaller probabilities will take a longer time to converge to their expected frequencies. And even though you say you don’t trust your mathematical background too much, I can see that your intuition is biting at something important here.
Namely, just because a certain bet has a positive expectation, it doesn’t always follow that you should take the bet. In fact, this doesn’t even always depend on whether the probability is small or large. For example, imagine someone offers you the following bet. A coin that is biased to come up heads with a probability of 0.99 will be tossed. If it comes up heads, you win 10 million USD. If it comes up tails, you have to pay 10 million USD. Would you take this bet?
Even though the expected value is very large, my guess is that most people who aren’t millionaires would think very hard before accepting such a bet. Since, practically speaking, the positive impact of earning 10 million will be quite small compared to the negative impact of losing 10 million, which would financially cripple you for the rest of your life.
But if you were allowed to play the bet many times, then you would probably take the opportunity immediately. On the other hand, if you were already, say, a billionaire, you would probably take the bet even for a single repetition, without hesitation. This all boils down to a concept in professional gambling called bankroll management. It is related to picking and sizing your bets such that no single bet can take too large a chunk of your overall money so that you can continue playing the game and allow the LLN to “do its job”. I addressed this issue (as well as the overall topic of how to treat unrepeatable events) in more detail under that Facebook comment I mentioned in my previous reply. Please take a look and let me know if it addresses some of your concerns.
Now, coming back to the Monty Hall problem – you acknowledge that with the 3-door example the odds of finding the reward if you switch are 2:1. In your last reply you said that you would definitely switch in the case of 1 million doors but you would be indifferent if the doors were only 3. But why? Surely, the difference is only quantitative and you still have a higher expectation of finding the reward if you do switch. And a probability of 2/3 is significantly larger than 1/2 (let alone 1/3), so I would say that even for the 3-door example you should also choose to switch, shouldn’t you?
Imagine we changed the rules of the game such that there is still a reward behind one of the doors but, instead of a goat, there’s a 10 million USD debt waiting for you behind the remaining 2 doors. Then, once you make your initial choice and the host opens one of the remaining 2 doors, would you still be indifferent between switching and staying?
Thanks for the clearly explained article.
One question that bothers me with the various explanations of the law of large numbers, i.e., how does one know what the “actual” probability is in the first place? The law seems to assume there is some pre-existing mean to which one can converge given enough experiments. The argument is circular in some sense.
Hi, Steve!
Alright, let’s think about your question. On the one hand, we have the concept of “a probability”. On the other hand, there’s the concept of “a long-term relative frequency”. What bothers you is that the two are often defined in terms of each other, right? That’s definitely a legitimate concern. If the law of large numbers is about relating the two (namely, the long-term frequency approaches the probability), we’d better also have independent definitions for the two concepts, otherwise we’re really just chasing our tails.
Since the definition of a long-term relative frequency of an event is straightforward and can be defined without using probabilities, it remains to also define probabilities without using long-term frequencies.
Now, there is the mathematical definition of probabilities which makes no reference to frequencies. Namely, the Kolmogorov axioms. So far so good. But the mathematical definition is rather abstract and we’re interested in also having a definition that is somehow related to the real physical world. Because, after all, the definition of “long-term frequency” can easily be related to the real world.
So, when it comes to a real-world definition of probabilities, there are currently 4 main views (plus the “classical definition” which preceded them). These views define probabilities as:
1. Long-term frequencies
2. Physical propensities
3. Subjective degrees of belief
4. Degrees of logical truth (i.e., statements whose truth value is neither ‘true’ or ‘false’, but there’s a degree of uncertainty)
Of these, only the first one uses the term “long-term frequency” in defining probabilities and the others don’t.
For example, the propensity definition will tell you that a 6-sided die which is a perfect cube with uniform density and rolled properly (without a bias) will have the same propensity of landing on each of its sides, hence the chances/probabilities of each side must be equal. And because the probabilities must sum up to 1 (coming from the mathematical definition), each side must have a probability (propensity) of 1/6 for coming up at any single roll. Notice, there hasn’t been a single mention of the term “long term frequency” in this paragraph so far.
What about the “frequentist” definition of probabilities? Does it have a circularity problem? Well, not really, since according to that definition the two concepts are simply identical. That’s why a pure Frequentist will tell you that you can’t assign probabilities to single events or hypotheses. The definition simply isn’t applicable to them. Though, as far as I know, there has been some “circularity” criticism towards the frequentist view of probabilities in philosophical discussions on the topic.
If these concepts are new for you, please check out my post on the definitions of probability (and maybe also my post on Frequentist vs. Bayesian approaches in statistics and probability). And, of course, let me know if this answers your question.
“The law of large numbers is a mathematical theorem but it’s probably not an incident that it actually has the word ‘law’ in it. I like to think about it in similar terms as some natural physical laws, such as gravitation.”
As a newbie about this entire domain of concepts and argumentations, I am not sure to be helped by
that kind of double face explanation as both a mathematical theorem and a physical law. What could it be a only mathematical understanding of the ‘theorem’ of large numbers? I mean, I understand that we are speaking about real valued functions which respect Kolmogorov’s axioms, don’t we? In terms of mathematical properties of such functions, what am I proving when I prove the law of large number?
Hi, Mario. That’s a good point. Please don’t take the quoted statement too literally, I was just trying to give an analogy between the law of large numbers and a physical law. The actual relationship between probability theory (and mathematics in general) and the physical world has always been a tricky subject. And there is a lot of philosophical debate on this topic.
It’s difficult to speak of pure mathematical properties when discussing the law of large numbers, since this theorem is making a statement about realizations of random variables, which do happen in the real world. Having said that, here’s an attempt for a short answer to your question.
Let’s take a discrete random variable X with an arbitrary probability mass function P(X=x). And now let’s assume we’ve generated n realizations of X, based on which we construct a new function Q(X=x) which is the relative frequency distribution of the realizations ( , where N(X=x) is the count of each of X’s possible outcomes).
, where N(X=x) is the count of each of X’s possible outcomes).
What the law of large numbers says is that, as n approaches infinity, the function Q will get closer and closer to the function P, in terms of mathematical properties. In a sense, the larger n is, the more you can use P and Q interchangeably without much loss in accuracy. This implies limits like and
and ![\overline{Q(x)} - \mathop{\mathbb{E}}[P(x)] \rightarrow 0](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%20156%2021'%3E%3C/svg%3E "Rendered by QuickLaTeX.com") , as n approaches infinity.
, as n approaches infinity.
Let me know if this is helpful (and if I understood your question right).
The law of large numbers vs The gambler fallacy
I recently Read about the gambler fallacy (that is the erroneous belief that if a particular event occurs more frequently than normal during the past it is less likely to happen in the future (or vice versa)), logically I understand that the probability doesn’t change.
lets take an example of tossing a fair coin, i do understand that with every toss the probability is 50%. but what confuses me is that by the law of large numbers with a large numbers of tosses the frequencies of heads and tails would be the same.
but lets consider the scenario that i flipped the coin say a million time and i have far more heads that tails, then by the law of large numbers somehow the number of tails and heads needs to sort out and i will have to get more tails than tails. isn’t somehow this indicates that the probability for tails do increase? and the gambler’s fallacy do occur?
can you please explain it to me because it confuses me. and what is the right way to think about the example I represented.
thanks
Hey Mohammed, great question. This is indeed something that at first looks like a paradox and many people have wondered about it. A coin doesn’t have memory and each flip is independent of the previous ones. Yet, by the law of large numbres (LLN), the coin somehow “remembers” that its long-term heads frequency should be close to 50% and the outcomes somehow sort themselves out to achieve that in the long run. How does it work?
The crucial thing to note about the LLN is that its claims are only valid for an infinite number of repetitions of a random trial. It makes no guarantees for any finite number of repetitions. For example, if you flip the coin only 6 times, you can easily get 5 heads, even though getting 3 is more likely. I’m not telling you anything new so far, you probably understand this well enough already. But keep it in mind for my main argument below. Let’s take your example and work with it.
Say you flipped a coin 1 million times and you happen to get 510 000 heads. Instead of 0.5, the relative frequency has so far converged to 0.51. But the LLN tells us that if we flip the coin for long enough, this frequency will somehow find a way to get back to values closer to 0.5. Does this mean the law promises that the next million flips will have to contain about 490 000 heads to balance the exaggerated result from the previous block of flips? Well, no, not the next one necessarily. What the law does promise, however, is that if you never stop flipping it, at some point you will hit a block of 1 million flips that has about 490 000 heads (do you agree?). In other words, the 490k-heads block that we need to “balance” the 510k-heads block will at some point come, you just need to give it time. I’m obviously simplifying things a lot here, but the point I’m trying to make is that, with infinite number of flips, all possible blocks are bound to occur. Those that have close to 500k heads, those with exactly 500k heads, those with 490k/510k heads… Yes, even those with 0 or 1 million heads! And after an infinite number of repetitions, all those blocks will balance each other to achieve the exact relative frequency of 0.5.
Now, in the real world we can’t really repeat things an infinite number of times, but that’s not a big problem because the probability of getting an untypical sequence itself decays as the number of repetitions increases. Let’s say the true probability is P and the relative frequency after N flips is RF. We can define an error term E = |P – RF|. For every possible threshold T between 0 and 1, the probability of having an E greater than or equal to T becomes less likely as N increases (do you agree?).
Like I said in the last section, how many repetitions guarantees a good enough convergence is very much dependent on the particular problem. For a coin flip, we all agree that 10 flips isn’t sufficient for the LLN to show itself. But even as few as 1000 flips is usually enough. For other problems, even a trillion repetitions might be insufficient.
Let me know if this answers your question at least at an intuitive level. Feel free to ask any clarifying questions.
I think I got the idea, correct me if I am wrong but the underlying intuition and reason for why the law of large numbers really works is because of the infinite flips (infinite number of repetitions of a random trial) we are guaranteed to get every possible combination of heads and tails and every such combination will balance each other in order to get to the 0.5 tails and heads (the right probability)?
Yep, this is more or less the informal intuition. And when it comes to finite repetitions, the larger N is, the better representative the sample would be of the hypothetical infinite population.