 A few posts ago I introduced you to the “three M’s” of statistics — the concepts of mean, mode, and median. Today I want to talk to you about a related concept called variance.
A few posts ago I introduced you to the “three M’s” of statistics — the concepts of mean, mode, and median. Today I want to talk to you about a related concept called variance.
While the three M’s measure the central tendency of a collection of numbers, the variance measures their dispersion. That is, it measures how different the numbers are from each other.
Measuring dispersion is another fundamental topic in statistics and probability theory. On the one hand, it tells you how much you can trust the central tendency measures as good representatives of the collection. High variance usually means a lot of the numbers in the collection will be far away from those measures.
But the importance of variance is far greater. It’s a central part of many tools and techniques in descriptive and inferential statistics, machine learning, data engineering, and so on.
In the following sections, I’m going to show the mathematical definition of variance with a few examples to give you an intuitive feel for it. To get the big picture, I’m also going to show a few alternative measures of dispersion.
This post is about measures of dispersion of finite collection of values. To see how that generalizes to probability distributions, check out my post on calculating the mean and variance of a probability distribution. Also, to see two very useful alternative representations of the variance formula, check out my post showing their derivation and intuition.
Table of Contents
Introduction
Let’s start with a funny (and not so realistic) example.
Imagine our technology has advanced so much that we can freely travel in space. We’ve started colonizing and populating new planets.
You’re bored of living on Earth and decide to take off towards another planet. You’re kind of an adventurous person and you don’t have too many capricious demands regarding where you want to live next. The only important thing for you is that the typical temperature on the new planet shouldn’t be anything crazy.
You’ve heard, for example, that the average temperature on Saturn is around -180° Celsius. You definitely don’t want to go there. You’ve also heard that the average temperature on Venus is around 450° Celsius and you certainly don’t want to go there either!
Then you hear about this newly discovered planet called Discordia. You read that the average temperature there is 25° Celsius. Perfect, that’s exactly what you were looking for. Without wasting any more time, you pack your bags and catch the first space ship.
You arrive at your destination only to find the current temperature on Discordia is 85° Celsius. Whoa, what’s going on?
Now that your expectations have been violated, you decide to look into this situation more carefully. Was the 25° Celsius average a lie?
 After some investigation, you find that on Discordia there’s a big temperature difference between days and nights. The average temperature at night is -40° Celsius and the average temperature during the day is 90° Celsius. The average of those 2 numbers is indeed
After some investigation, you find that on Discordia there’s a big temperature difference between days and nights. The average temperature at night is -40° Celsius and the average temperature during the day is 90° Celsius. The average of those 2 numbers is indeed  . So, your information wasn’t inaccurate after all.
. So, your information wasn’t inaccurate after all.
Then you decide to look at the day/night temperatures for the past 10 days:
- -44
- 87
- -25
- 85
- -31
- 92
- -31
- 89
- -30
- 99
- -33
- 94
- -40
- 88
- -37
- 84
- -41
- 90
- -37
- 89
This looks terrible. Even though the average temperature (when you mix days and nights) is around 25° Celsius, you never get to experience that or anything near it. At different times, the actual temperature keeps jumping between extreme cold and extreme hot!
What was your mistake? Instead of only looking up the average temperature on Discordia, you should have also investigated the temperature’s variability. In other words, you needed a measure of its dispersion.
Measuring dispersion
For a collection of numbers to be dispersed simply means that the numbers are far away from each other. Dispersion means variability.
So, what should a measure of the variability of a collection of numbers look like? Let’s think about it.
When is the variability lowest? Well, when all the numbers in the collection are actually the same number. Something like [2, 2, 2, 2], [5, 5], [1, 1, 1], and so on. You can’t get any more similar than that, so in this situation the measure should be at its lowest. This implies that the measure of dispersion must have an absolute minimum. And what better number to represent a minimum than 0?
Does the measure also have an absolute maximum? Not really. An arbitrary collection can be arbitrarily large and the numbers can be as different from each other as you want.
From this we conclude that any measure of dispersion should be between 0 and ∞ (positive infinity).
Another property this measure must have is to increase when the numbers get more different from each other and decrease when they get more similar. If that’s not the case, then our measure isn’t really sensitive to dispersion but to something else.
With these 2 properties in mind, let’s take a look at some typical measures of dispersion in statistics. In order to have something to measure, I’m going to use the following example collection of numbers for all measures:
- [1, 4, 4, 9, 10]
The range
The range of a collection of numbers is defined as the difference between the maximum and the minimum value in the collection. In our example collection, the largest number is 10 and the smallest is 1. So, its range is 10 – 1 = 9.
Let’s see if this definition conforms to the 2 properties.
First, if all numbers in the collection were the same (for example, [1, 1, 1, 1, 1] or [10, 10, 10, 10, 10], the minimum and the maximum would also be the same (both 1 or both 10). And subtracting a number from itself always results in 0. This property holds.
What about the second property? If you think about it, the only way to change the range of a collection is if you change its minimum or maximum values. For example, if we changed [1, 4, 4, 9, 10] to [3, 4, 4, 9, 10], the range would become 10 – 3 = 7. If we changed it to [1, 4, 4, 9, 20], the range would become 20 – 1 = 19. As the numbers become more dispersed, the range increases, and vice versa. Which is what we would expect from a measure of dispersion.
But this particular measure isn’t at all sensitive to changes of values other than the minimum or the maximum. For example, if you changed the collection to [1, 1, 1, 1, 10], the range is still 10 – 1 = 9, even though the variability in the collection looks rather different (lower) now.
The mean absolute difference
The mean absolute difference of a collection of numbers is the arithmetic mean of the absolute differences between all pairs of numbers in the collection. I’m going to show how to calculate it for our example collection [1, 4, 4, 9, 10].
First, let’s list all possible absolute differences:
- 1
- |1 – 1| = 0
- |4 – 1| = 3
- |4 – 1| = 3
- |9 – 1| = 8
- |10 – 1| = 9
- 4
- |1 – 4| = 3
- |4 – 4| = 0
- |4 – 4| = 0
- |9 – 4| = 5
- |10 – 4| = 6
- 4
- |1 – 4| = 3
- |4 – 4| = 0
- |4 – 4| = 0
- |9 – 4| = 5
- |10 – 4| = 6
- 9
- |1 – 9| = 8
- |4 – 9| = 5
- |4 – 9| = 5
- |9 – 9| = 0
- |10 – 9| = 1
- 10
- |1 – 10| = 9
- |4 – 10| = 6
- |4 – 10| = 6
- |9 – 10| = 1
- |10 – 10| = 0
Now let’s take their average. First, we need to sum all the differences:
- 0 + 3 + 3 + 8 + 9 + 3 + 0 + 0 + 5 + 6 + 3 + 0 + 0 + 5 + 6 + 8 + 5 + 5 + 0 + 1 + 9 + 6 + 6 + 1 + 0 = 92
Then, we simply divide by 25 (the number of terms) to get the average:
![\[ \frac{92}{25} = 3.68\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-0e2d8f8c8a8b522343f95035310cfa5f_l3.png "Rendered by QuickLaTeX.com")
Notice it gives quite a different value compared to the range.
From some perspective, you can see the mean absolute difference as a generalization of the range. How? Well, instead of only looking at the difference between the most extreme values, here you take into account the differences between all numbers in the collection. And now this measure is also going to be sensitive to changes in all values, not just the minimum and the maximum.
Here’s the general formula for the mean absolute difference:
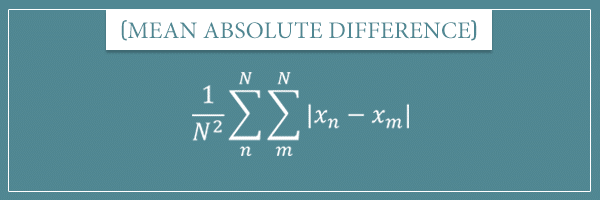
If you’re not familiar with the sum operator Σ, check out my post about the sum operator. And don’t be scared by the double sum here. All it means is that, for every n in the outer sum (the one on the left), the inner sum will go from m=1 to N.
The reason we’re dividing by  is because there are
is because there are  ways in which you can combine all N numbers in pairs (when a number can also be paired with itself). If you need a refresher on combinatorics, you will find my post on the topic useful.
ways in which you can combine all N numbers in pairs (when a number can also be paired with itself). If you need a refresher on combinatorics, you will find my post on the topic useful.
And, of course, if you have any questions about any of this, don’t hesitate to ask in the comment section below.
The mean absolute deviation
So far, I’ve shown 2 different measures of dispersion. There are many more, but as a warm-up for introducing the variance, I’m going to show you a third way.
The measures I’ve shown so far try to compare different values in the collection. But what if we came up with a measure that compares all numbers to some unique and special number?
This is the idea behind the mean absolute deviation.
(By the way, don’t be confused about the similarity in names with the mean absolute difference — they are two different measures.)
So, what is this special number I’m talking about? Well, most of the time it’s one of the measures of central tendency. And, as you know, the most common measures of central tendency are the mean, the mode, and the median.
Here’s the general formula for the mean absolute deviation:
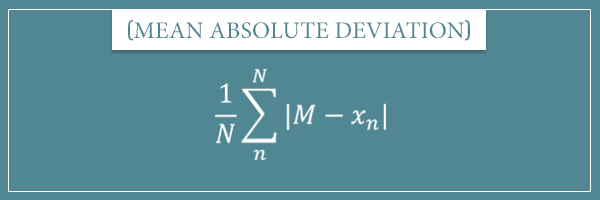
Here M stands for any measure of central tendency. Since we’re taking the absolute value of the difference, we can also write the expression inside the sum operator as:
![\[ |x_n - M| \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-c035f311f67e90c577af1172f9dea6dc_l3.png "Rendered by QuickLaTeX.com")
Let’s calculate this measure for our example collection [1, 4, 4, 9, 10] around the three M’s.
Mean absolute deviation around the mean
First, the mean of [1, 4, 4, 9, 10] is:
![\[\frac{1 + 4 + 4 + 9 + 10}{5} = \frac{28}{5} = 5.6\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-33c5290fd731a07292269f6bfb80dff0_l3.png "Rendered by QuickLaTeX.com")
The corresponding absolute differences are:
- |1 – 5.6| = 4.6
- |4 – 5.6| = 1.6
- |4 – 5.6| = 1.6
- |9 – 5.6| = 3.4
- |10 – 5.6| = 4.4
Finally, the mean of these differences is:
![\[\frac{4.6 + 1.6 + 1.6 + 3.4 + 4.4}{5} = \frac{15.6}{5} = 3.12\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-6520283d519e6d9770c8e3530f94e54b_l3.png "Rendered by QuickLaTeX.com")
Mean absolute deviation around the median
The median of [1, 4, 4, 9, 10] is the middle value, which is 4. Here are the absolute differences:
- |1 – 4| = 3
- |4 – 4| = 0
- |4 – 4| = 0
- |9 – 4| = 5
- |10 – 4| = 6
And their mean is:
![\[\frac{3 + 0 + 0 + 5 + 6}{5} = \frac{14}{5} = 2.8\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-f3ab6ce2d0735d45bc133312869bef44_l3.png "Rendered by QuickLaTeX.com")
Mean absolute deviation around the mode
In this case, the mode (the most common value) happens to be equal to the median, so the calculations will be exactly the same. Hence, the mean absolute deviation around the mode for [1, 4, 4, 9, 10] is also equal to 2.8.
A quick recap
Let’s compare what each measure gave as the coefficient of dispersion for our example collection [1, 4, 4, 9, 10]:
- 9 (range)
- 3.68 (mean absolute difference)
- 3.12 (mean absolute deviation around the mean)
- 2.8 (mean absolute deviation around the median)
- 2.8 (mean absolute deviation around the mode)
As you can see, they all measure the dispersion in the collection somewhat differently. But which one is the most accurate? Which ones should you trust more and under what circumstances?
I’ll come back to this question towards the end. But before that, let’s finally introduce the main hero of this post.
The variance
The variance is arguably the most commonly used measure of dispersion. Now that we have some other measures to compare it with, let’s build its definition step by step.
First, similar to mean absolute deviation, the variance also measures deviations from one particular central tendency. Namely, the mean of the collection. Therefore, we will again take the differences between the mean and each number.
Did you wonder why the mean absolute deviation takes the absolute value of the differences? Why not simply sum the positive and negative differences together?
It’s probably not hard to see the problem. If you didn’t take the absolute values, positive and negative differences will be canceling each other out. For example, consider this collection:
- [1, 2, 3]
Its mean is equal to 2. Let’s see what happens when we sum the actual differences:
- 1 – 2 = -1
- 2 – 2 = 0
- 3 – 2 = 1
Then, the total deviation is  .
.
So, we got a measure of 0, which is exactly what we would have gotten if we had the collection [2, 2, 2]. In other words, this isn’t really a measure of dispersion at all. It completely disregards the second required property for any measure of dispersion. Namely, as the numbers get more different from each other, the measure should increase in value.
Okay, we know we can’t sum the actual differences from the mean and still have a measure of dispersion. But taking the absolute value isn’t the only thing you can do. There are other mathematical operations which also always result in positive numbers.
The variance is an example of a measure that uses one such operation.
The mathematical definition of variance
Calculating the variance is equivalent to calculating mean absolute deviation around the mean, but instead of taking the absolute value of each difference, here you simply square it.
In other words, the variance is defined as the mean of the squared differences between the mean and individual numbers in the collection:
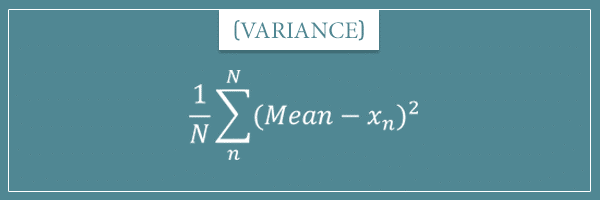
Why square the differences? Well, because squaring a negative number always gives a positive number. Hence,  is the same as
is the same as  .
.
Of course, by squaring the differences, you aren’t just making sure they’re all positive. You’re also inflating the contribution of each difference to the final sum (and mean). Let’s see this for our example collection [1, 4, 4, 9, 10].
We had calculated its mean as 5.6. Here are the squared differences with the mean:
- (1 – 5.6)2 = 21.16
- (4 – 5.6)2 = 2.56
- (4 – 5.6)2 = 2.56
- (9 – 5.6)2 = 11.56
- (10 – 5.6)2 = 19.36
The average of the squared differences is:
![\[\frac{21.16 + 2.56 + 2.56 + 11.56 + 19.36}{5} = \frac{57.2}{5} =11.44\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-2cda0f4e88839ac61f26cdb74350d94c_l3.png "Rendered by QuickLaTeX.com")
The standard deviation
Do you notice something? The variance of this collection is larger than all other measures I introduced. The reason, of course, is the squaring operation. Essentially, the variance is no longer in the same unit of measurement as the members of the original collection, but in the square of the unit.
To resolve this, let’s introduce another measure of dispersion called the standard deviation. This measure is simply defined as the square root of the variance.
Therefore, for our example, the standard deviation of the collection is √11.44 ≈ 3.38.
By taking the square root, we get the measure back on the same scale as the original collection, as well as the other measures. Now that we’re on the same scale, this measure’s value is comparable to the others.
The standard deviation is tightly related to the variance, but they’re still different measures used for different purposes. But I don’t want to deviate from the topic of the current post too much, so I’m going to leave this for another post.
Discussion
Let’s see how our new list of measures compares for the example collection we started out with.
- 9 (range)
- 3.68 (mean absolute difference)
- 3.12 (mean absolute deviation around the mean)
- 2.8 (mean absolute deviation around the median)
- 2.8 (mean absolute deviation around the mode)
- 3.38 (standard deviation)
(And, of course, the variance, which we calculated as 11.44, but is on a different scale).
Even though they’re all on the same scale, the value of the range might still be sticking out to you as larger than all the others. This isn’t an accident and is true for any collection.
The proof of this isn’t too hard, but it’s slightly mathematically hairy and I don’t want to overwhelm you with long expressions. However, the intuition is quite simple.
As you might remember from my mean, mode, median post, these three measures are always within the range of the collection. That is, the mean, the mode, and the median are always greater than or equal to the smallest value in the collection and less than or equal to the largest value in the collection.
Therefore, the absolute difference between any number of the collection and any measure of a central tendency will also always be less than the range. So, the mean of those absolute differences will itself be within the range.
The same reasoning holds for the mean absolute difference, even though there the absolute differences are taken between all values. Since the distance between any pair of values is less than or equal to the range, their average will also be less than or equal to the range.
The situation with the standard deviation is a bit different in nature because of the nonlinear transformations of squaring and taking the square root, but in the end the intuition is very similar and it can also never exceed the range.
In a way, you can view the range as the ceiling for any other measure of dispersion which is on the same scale as the collection. In other words, it serves as an upper bound for those measures (just like 0 is their lower bound).
When you have a collection of numbers and want to measure their coefficient of dispersion, the range will give the roughest possible estimate by simply reporting the length of the spread of the numbers. Each of the other measures reduces the coefficient based on the dispersion of the numbers within the range. And each of the measures has its own way of doing it.
Because of this, each measure will be sensitive to a slightly different aspect of the variability in the collection. For example, some measures may be more sensitive to outliers than others. In other contexts, some measures fit more nicely with certain formulas and calculations. In fact, this is one of the main reasons for the popularity of the variance (and the standard deviation).
But to not make this post even longer, I don’t want to go too deep into these topics here and I’ll instead leave them for future posts.
Summary
Measures of dispersion try to put a number on the degree to which values in a collection are different from each other.
In this post, I introduced a few of these measures with the goal of building up to the most popular one: the variance. I tried to select a subset of existing measures that gives a good feel for measures of dispersion in general, while keeping the list small.
For any collection of values:
- The range measures the difference between the largest and smallest value.
- The mean absolute difference measures the arithmetic mean of the absolute differences between all pairs of numbers.
- The mean absolute deviation measures the arithmetic mean of the absolute differences of individual values and a central tendency (like, the mean, the mode, and the median).
- Finally, the variance (and its square root, the standard deviation) measures the square of the differences between the mean and individual values.
For a measure to be a measure of dispersion it has to satisfy 2 requirements. First, it has to have a minimum at 0 whenever all values in the collection are the same. Second, as the values become more different from each other, the measure has to increase.
There are many other measures of dispersion I haven’t talked about here. For example, some involve taking the median (instead of the mean) absolute deviation around a central tendency. Others might take a different approach to overall spread compared to the range, for example by first discarding the bottom and top 25% of the sorted values in the collection (called the interquartile range).
Each measure of dispersion has different properties which might be more or less useful, depending on the field of application. But, a bit more practically, you can view measures of dispersion as tools to tell you how much you can trust a central tendency to represent the entire collection. The higher the dispersion in the collection is, the less any measure of central tendency will resemble the specific numbers in the collection.
Well, this is it for this post. Feel free to leave any remarks or questions in the comment section below.
Until next time!
Hi,
The discussion seems to be very useful. But i am not clear with conclusion like which is best whether based upon application ? and what is the purpose of finding measures of dispersion ?
Sorry if my question is very basic since i am a beginner.
Thanks.
Hi Murugappan, there’s no need to apologize for asking basic questions, it’s all in the game 🙂
The purpose of measuring dispersion/variability is, in a way, the same as the purpose for measuring anything. To guide our decisions when our decisions depend on the thing we’re measuring. For example, what is the purpose of measuring ambient temperature? Well, for example it’s useful for decisions like the types of clothes to wear. Or why measure weight? Maybe to determine if a particular platform is capable of supporting an object of a particular weight. To give a somewhat more statistical example – why do we measure central tendencies (like mean, mode, and median)? Roughly speaking, to have an idea of the value of a “typical” member of a particular collection. And, in this sense, the purpose of measuring dispersion is to have an idea of how likely it is that two randomly chosen members will have the same values (or values close to each other). These are more practical, real-world type of reasons. There are also more technical reasons for wanting to measure dispersion. For example, you can use the variance to determine the accuracy of a particular statistical algorithm for parameter estimation.
As to the first question, I simply meant that some of those measures will be more appropriate than others depending on the problem you’re solving, the type of data you have, and so on. For example, if the data is generally very skewed, has more than one mode, or has some significant outliers, measures based on the median might be more appropriate than ones based on the mean.
I’m trying to give a general enough answer but let me know if you have a more specific question (or if I’m missing your actual question).