 You can think of probabilities as measures of uncertainty in the occurrence of an event, the truth of a hypothesis, and so on.
You can think of probabilities as measures of uncertainty in the occurrence of an event, the truth of a hypothesis, and so on.
These measures are numbers between 0 and 1. Zero means the event is impossible to occur and 1 means the event is certain to occur.
If you have many events of interest, you can measure their probabilities separately, but you can also measure probabilities of different combinations of these events.
Say you’re following the national soccer championships of England, Spain, and Italy. You want to calculate the probabilities of Arsenal, Barcelona, and Juventus becoming national champions next season. These probabilities are:
- P(Arsenal)
- P(Barcelona)
- P(Juventus)
But what if you want to calculate the probability of both Arsenal and Barcelona becoming champions? Or the probability that at least one of the three teams does?
In this post, I’m going to show how probabilities of such combinations of events are calculated. I’m going to give the general formulas, as well as the intuition behind them. To do that, I’m first going to introduce a few relevant concepts from probability theory.
The most important concept is that of compound events. These are events formed by two or more “smaller” events, by requiring that either all or some of them occur.
Table of Contents
Compound events
A compound event consists of two or more simpler events. You can construct a compound event by connecting the simpler events with two types of relations:
- and relations
- or relations
The and relation represents the occurrence of all events that form the compound event, whereas the or relation represents the occurrence of at least one of the events.
For example, the probability of the compound event that both Barcelona and Juventus become champions is:
- P(Barcelona and Juventus)
The event “Barcelona and Juventus” will occur only if both teams become champions in their respective national leagues. The official term for these kinds of probabilities is joint probabilities.
Similarly, the probability of at least one of those two teams becoming a champion is:
- P(Barcelona or Juventus)
In this case, the event “Barcelona or Juventus” will occur if one or both teams become champions.
Of course, you can combine as many events as you want:
- P(Arsenal and Barcelona and Juventus)
- P(Barcelona or Arsenal or Juventus)
- P(Arsenal and (Barcelona or Juventus))
- Etc.
In probability theory, the most common notation used for and relations is ∩ and for or relations it is ∪. These symbols come from set theory (where probability theory is ultimately defined) and represent the intersection and union operations on sets.
With this notation, the first probability above would become P(Barcelona ∩ Juventus) and the second would become P(Barcelona ∪ Juventus). However, I’m only giving this notation so you know it exists and recognize it when you see it elsewhere. I’m not going to enter the territory of set theory in this post and, for readability purposes, I’m going to continue using the and/or notation.
Non-overlapping events
Two events are non-overlapping if it’s impossible for both of them to occur. The concept can be extended to more than two events. For example, there can only be a single winner of La Liga (the Spanish soccer championship) each year, so the events representing different teams winning it are completely non-overlapping.
When visually representing the sample space of non-overlapping events, naturally the areas representing their probabilities also don’t overlap:

In a visual representation of a sample space, the probability of an event can be expressed as the area representing the event divided by the total area of the sample space (the whole square):

Life can be made easier by assuming the area of the sample space is equal to 1. In that case, the areas of the events will directly correspond to their probabilities. For simplicity, I’m going to make that assumption for the rest of this post.
To continue the metaphor, an event occurs if a randomly picked point from the entire sample space happens to be in the rectangle representing the event.
And relations
If two events overlap, the area of their overlap is equal to the probability of the compound event formed by both events. So, the first important conclusion is that the probability of two non-overlapping events is equal to zero. For example:
- P(Barcelona and Real Madrid) = 0.
This just captures the intuitive understanding that two teams can’t both become champions of the same league in the same year.
Or relations
Calculating the probability of at least one of two or more non-overlapping events is also simple — it’s just the sum of the individual probabilities:
- P(Barcelona or Real Madrid) = P(Barcelona) + P(Real Madrid)
One of the two teams will become the Spanish champion if a randomly chosen point from the sample space happens to be inside one of the rectangles representing the two teams. So, the probability that the point will be in at least one of the rectangles is equal to the sum of the two areas.
Overlapping events
Consider an example where two events do overlap. You might want to know the probability of both Barcelona and Juventus winning their respective leagues.
This time, we’re comparing probabilities of teams competing in different championships. This means both teams can become champions in the same year. Here’s what a possible sample space might look like:
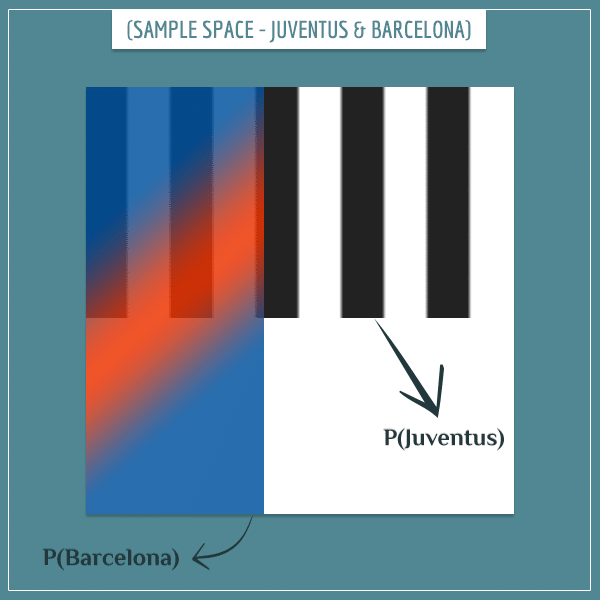
This, in essence, is the sample space of all possible compound events formed by the simple events:
- Barcelona wins La Liga
- Juventus wins Seria A
And relations
The event “Barcelona and Juventus” occurs with probability equal to the area of overlap between the two events:
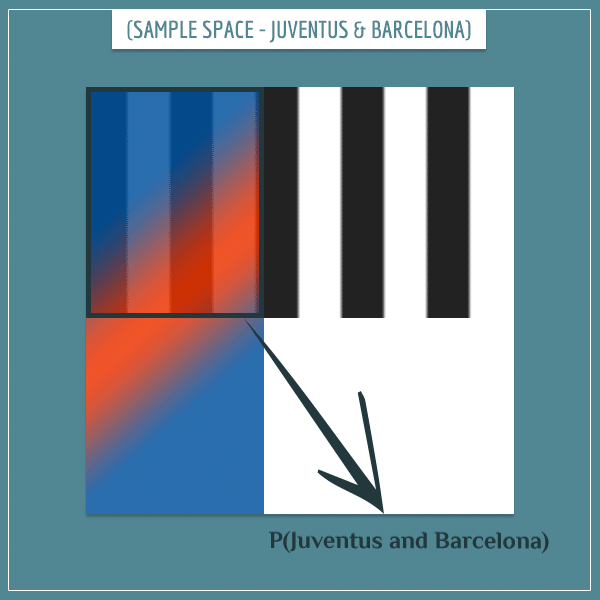
How is this probability actually calculated? In a previous post, I gave a detailed explanation for the answer to this question, so, I’m going to get straight to the punch line:

The term P(Event-2 | Event-1) is the conditional probability of Event-2, given Event-1.
With this definition, the probability of Juventus and Barcelona becoming champions can be expressed as:
- P(Juventus and Barcelona) = P(Juventus) * P(Barcelona | Juventus)
And also with the equivalent expression:
- P(Juventus and Barcelona) = P(Barcelona) * P(Juventus | Barcelona)
Or relations
The last type of probability to explain is P(Event-1 or Event-2), if the two events overlap:
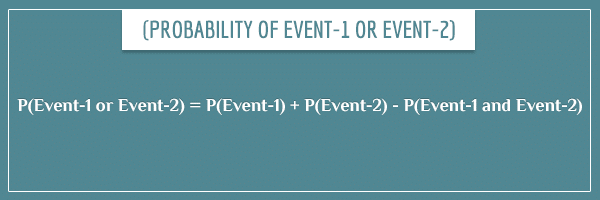
The intuition behind subtracting the probability of the overlap between the two events is that you would be counting its area twice if you didn’t. I’ll explain what I mean visually. Consider the sample space of two random events A and B:
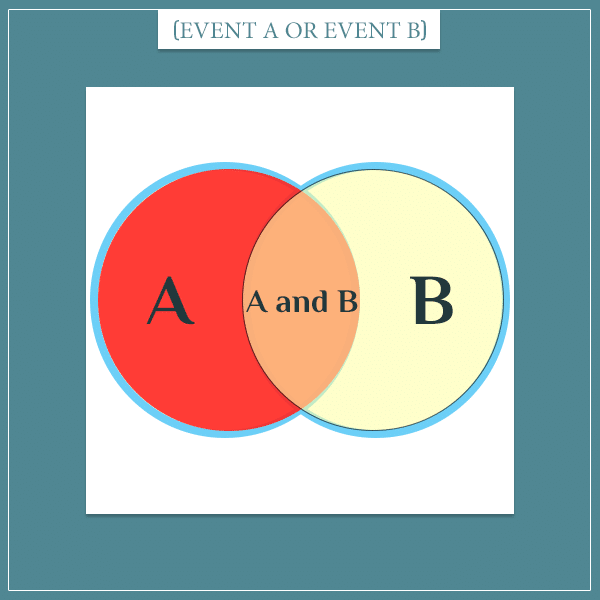
The probability of A or B is equal to the area outlined in blue. If you add the areas of the two circles, you will get more than that area because you will have counted the intersection (area of overlap) twice: once for each circle. Then, to get to the true probability, you just need to subtract the area of overlap once, so in the end it’s counted exactly once.
But the area of overlap is precisely P(A and B), so you see why the final probability should be:
- P(A or B) = P(A) + P(B) – P(A and B)
When the events are non-overlapping, P(A and B) is equal to 0 (as I showed in the previous subsection) and the formula reduces to:
- P(A or B) = P(A) + P(B)
The last thing I want to briefly talk about before closing this section is the concept of dependence between two events.
Event (in)dependence
The definition of dependence in probability theory is somewhat different from its usage in natural language, or even in science. Here, two events are independent if (and only if) knowing that one event has occurred doesn’t change the probability of the other. Mathematically, this is expressed as:
- P(Event-A | Event-B) = P(Event-A)
So, if two events are independent, each event’s probability remains the same, regardless of the other event’s occurrence. For example, Barcelona becoming champion in Spain is (mostly) independent of Juventus becoming champion in Italy. These two ways of expressing their independence are equivalent:
- P(Barcelona | Juventus) = P(Barcelona)
- P(Juventus | Barcelona) = P(Juventus)
On the other hand, if two events are dependent, knowing that one of them has occurred does change the probability of the other. For example, knowing that the weather is cloudy changes the probability of rain:
- P(Rain | Cloudy Weather) > P(Rain)
In this case, the probability increased, but it can also decrease:
- P(Rain | Sunny Weather) < P(Rain)
In general, any time knowing the probability of one event increases or decreases the probability of another event, the two events are dependent.
In probability theory, the term dependence doesn’t imply any causal relationship between two or more events.
General formulas for compound events
In this section I’m going to give the general formulas for calculating probabilities of compound events formed by two or more simpler events.
Compound events connected with and relations
I’m starting with with a single event, and adding a new event at every line. Try to catch the pattern before looking at the explanation afterwards.
P(A) = P(A)
P(A and B) = P(A) * P(B | A)
P(A and B and C) = P(A) * P(B | A) * P(C | A and B)
P(A and B and C and D) = P(A) * P(B | A) * P(C | A and B) * P(D | A and B and C)
The general pattern
Basically, you multiply all events, each conditioned on all previous events. In this case, P(A) is unconditional because it’s the first element. But the order really doesn’t matter. The letter labels are arbitrary
Still, in practice some orders are more appropriate, based on the actual dependency structure between the events.
To see where this formula comes from, here’s the step-by-step expansion of the third line above:
- P(A and B and C) = P(A and B) * P(C | A and B)
- P(A and B) = P(A) * (B | A)
- P(A and B and C) = P(A) * P(B | A) * P(C | A and B)
In the last step, I substituted P(A and B) in the first equation with the right-hand side of the second equation. The trick is to treat the compound event “A and B” as a regular event (which it is) and apply the formula for calculating joint probabilities to the events “A and B” and “C”:
- P((A and B) and C)
One special case for calculating the joint probability of events is when all of them are mutually independent. Then the formula reduces to the product of the probabilities of individual events:
- P(A and B and C and … and Z) = P(A) * P(B) * P(C) * … * P(Z)
Can you see why? Hint: what is P(B|A) if A and B are independent?
Compound events connected with or relations
Like in the previous section, I’m going to give the general pattern in a bottom-up fashion by starting from a single event and adding another event at each line. This time I’m going to use simple color coding to make the pattern more visible (and the equations more readable):
P(A) = P(A)
P(A or B) = P(A) + P(B) – P(A and B)
P(A or B or C) = P(A) + P(B) + P(C) – P(A and B) – P(A and C) – P(B and C) + P(A and B and C)
P(A or B or C or D) = P(A) + P(B) + P(C) + P(D) – P(A and B) – P(A and C) – P(A and D) – P(B and C) – P(B and D) – P(C and D) + P(A and B and C) + P(A and B and D) + P(A and C and D) + P(B and C and D) – P(A and B and C and D)
The general pattern
The idea here is much simpler than it seems:
- Group the events into singles, pairs, triplets, quadruplets, and so on.
- Add or subtract all possible combinations of each grouping in ascending order, starting from addition and taking turns (among the two operations).
In other words, you add all singles, then subtract all pairs, then add all triplets, then subtract all quadruplets, and so on. And you write all terms out until you reach the largest group (all elements connected with and relations as a single event).
The intuition here is the same as the one I gave when I first introduced overlapping events. Each term corrects for counting a particular area (corresponding to a joint probability) too many or too few times.
A special case is when all events are mutually non-overlapping. Then all higher-order groupings are equal to zero (non-overlapping events are mutually exclusive) and the formula reduces to:
- P(A or B or C or … or Z) = P(A) + P(B) + P(C) + … + P(Z)
Summary
This was a heavy post, especially if you’re new to the subject. However, everything I talked about can be summarized with the following definitions:
- Compound events: events formed by 2 or more simpler events. The simpler events can be connected with:
- And relations: all events in the compound event occur.
- Or relations: at least one of the events in the compound event occurs.
- Event overlap:
- Non-overlapping events: a set of events of which only one can occur (aka, mutually exclusive events).
- Overlapping events: a set of events which can all occur simultaneously (mutually non-exclusive events).
- Event dependence:
- Independent events: a set of events where having information about one event doesn’t change the probabilities of the others.
- Dependent events: a set of events where having information about one event increases or decreases the probability of the others.
Finally, the general formulas for computing probabilities of compound events with and relations and or relations are:
- P(A and B and C …) = P(A) * P(B | A) * P(C | A and B) * P(D | A and B and C) * …
- P(A or B or C …) = P(A) + P(B) + P(C) – P(A and B) – P(A and C) – P(B and C) + P(A and B and C) – …
When building probabilistic models — or really doing almost anything related to probability — it’s impossible to get away with not working with compound events. So, understanding the concepts I introduced in this post is an important stepping stone for understanding more complicated concepts in probability theory and its related fields.
If you want to read about a specific application of compound event probabilities, check out my Bayesian belief networks post. Bayesian belief networks are a useful tool for propagating probabilistic information between sets of events which depend on each other.
Amazing. I was still bound to the idea that a dependent event was simply an overlapping event.
Thanks for the insight!
In the formula for the non-overlapping events
P(A or B and C or … or Z) = P(A) + P(B) + P(C) + … + P(Z) is a small mistake: shouldn’t the second and must be an or also? And if we are at the subject that they are non-overlapping shouldn’t this be xor?
Hi Lukas, good spot! That was just a typo. Sorry about that, I fixed it.
The XOR isn’t particularly relevant in this context. Think of the “or” relation as an alias for the union operation on sets. Roughly speaking, the purpose is to find the size of the subset of the sample space that covers the events connected with the “or” relation.
So, for example, “A or B or C” means “the union of A, B, and C”. And we use this union to calculate the probability of A or B or C (that is, the probability of at least one of the events occurring) by calculating what part of the whole sample space this union covers. Yes, if the events are all mutually non-overlapping, technically only one of them can occur, but “only one” is still consistent with “at least one”, so the general definition covers this special case as well.
Does this make sense?
Awesome article, finally a clear and complete explanation of calculations of compound probabilities. Thank you!
I am slightly confused by event overlap and event dependence. I feel these concepts are related. Can I think of overlapping events as dependent events and non-overlapping events as independent events?