
What does a probability of zero mean? When people use it in everyday conversations, a statement like “the probability of something is zero” usually implies that that something isn’t going to happen. Or that it is impossible to happen. Or that it will never happen.
There’s zero chance I’m passing this exam!
Is this true? Can we really say that zero probability events are impossible to occur? I’m going to show you that this is, in fact, false. You will see zero probability events are more than possible: they happen all the time.
I’m first going to give a general overview of the phenomenon and then trace its roots by introducing the concept of probability masses and probability densities. Though the first part is going to be fairly intuitive, the second part is going to be a bit heavy on the math side.
After reading this post, you can visit my related post on probability distributions where I give more intuition about probability masses and densities.
Table of Contents
Basic intuition
Let’s start with some simple probability examples. You’re flipping a coin and considering the probability of getting heads. The answer is easy:
![\[P(\textrm{"Flip heads"}) = \frac{1}{2}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-fdc534ab6e95b5f2c3adb4374290baec_l3.png "Rendered by QuickLaTeX.com")
You probably came up with this answer by a thought process like:
- There are only 2 possible outcomes. One of them is heads. Therefore, the probability of heads is 1 out of 2, or 1/2.
By the same logic, the probability of rolling a 4 with a 6-sided die is 1/6. The probability of drawing the jack of diamonds from a standard 52-card deck is 1/52. You get the idea.
The logic here is simply to divide the number of outcomes that satisfy an event by the total number of possible outcomes.
Zero probabilities
If an outcome isn’t in the set of possible outcomes, by definition it can’t occur. For example, you can’t roll an 8 with a 6-sided die. This means that P(“Roll 8”) = 0.
You can still get this probability by dividing by the total number of possible outcomes:
![\[P(\textrm{"Roll 8"}) = \frac{0}{6} = 0\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-ed6d39ccdcaa277c579f762572da30d1_l3.png "Rendered by QuickLaTeX.com")
The zero in the numerator comes from the fact that exactly 0 of the six possible outcomes are 8.
Have you noticed a contradiction so far? In the beginning I said that a probability of zero doesn’t imply an outcome is impossible to occur. But just now I implied that impossible outcomes always have a probability of 0. What’s going on?
The apparent contradiction is resolved by noticing that I approached the question from two different directions. It’s still true that impossible outcomes have a probability of zero. What is not true is that zero probability outcomes are necessarily impossible.
Possible outcomes with zero probabilities
So, how can an outcome be possible, yet have a probability of zero? You can’t come up with any examples while staying in the realm of finite sample spaces. On the other hand, in infinite sample spaces, possible zero probability outcomes are abundant.
A sample space is simply the set of all possible outcomes of some randomness or uncertainty. A finite sample space is one which has a finite number of possible outcomes. An infinite sample space has an infinite number of possible outcomes.
The simplest example of an infinite sample space I can think of is that of randomly drawing a number between 0 and 1. This sample space is infinite because there’s an infinite number of real numbers in the interval [0, 1].
So, what is the probability of drawing any specific number from this interval?
![A visual depiction of the interval [0, 1]](https://www.probabilisticworld.com/wp-content/uploads/2017/08/interval-0-1.png)
Do you already see a problem with applying the probability calculation logic from the previous section to answering this question? Because there is only one of each specific number in the interval, the numerator in the formula is still 1 . But when you try to divide this by the total number of possible outcomes, you suddenly find yourself in a situation of having to divide by infinity.
Dividing by infinity
Dividing by infinity is not a well-defined mathematical operation. What is well defined is the concept of limits. Discussing limits here is way beyond the scope of this post, but you can easily imagine that the larger the denominator is, the smaller the overall expression is going to be:
![\[\frac{1}{100} = 0.01\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-5e8b3e81249582786cc7fd37bb02d0c5_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{1}{10000} = 0.0001\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-f5c7eb6693ae0d86073e8ddef132e69d_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{1}{1000000000000 } = 0.000000000001\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-9e3fcd5a4621ae450c67824f85e03bd1_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{1}{\textrm{Infinity}} = ?\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-b08067b1904852c40963c56ec4ec0e4d_l3.png "Rendered by QuickLaTeX.com")
Clearly the answer to the last expression can’t be any positive real number. That would imply that the denominator was actually a finite positive number too, but we know it’s infinity.
But you can see that, as the denominator approaches infinity, the entire expression approaches zero. Therefore, if we’re going to attach a number to the last expression, zero seems like the most natural choice.
With this in mind, let’s go back to our finite sample space approach to calculating probabilities. If we try to squeeze the maximum out of it to extend to infinite sample spaces, we would get something like:
![\[P(\textrm{Any specific possible outcome}) = \frac{1}{\textrm{Infinity}} = 0\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-e0e8bbea4cbb94731871e2f19aad96d0_l3.png "Rendered by QuickLaTeX.com")
Notice, we have a probability of a possible outcome and it’s equal to zero. Voilà!
Of course, this is an informal explanation and you’re not truly satisfied with it. You can’t really divide a real number by infinity and this was only meant to give basic intuition. Furthermore, it still doesn’t really explain why possible and impossible events can both have a probability of zero.
I’m going to address these questions in the rest of this post. But before that, here’s a small intermezzo to clarify something that might be bugging you.
Why are we considering specific values?
Think about what it means to draw a specific number from the interval [0, 1]. Let’s say this number is 0.3875:
![\[P(0.3875) = ?\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-bc0e726aec9900dbf3d2ef379395b699_l3.png "Rendered by QuickLaTeX.com")
Remember, we’re talking about drawing this very exact number. If you draw 0.38750001, it doesn’t count. If you draw 0.387500000000000000000001, it still doesn’t count. It has to be exactly 0.3875 (with the optional infinite trail of zeros).
You might think I’m being picky. If the drawn number is close enough to the original number, shouldn’t we consider that a success? You can do that, of course. You can still count it as the same number if it’s less than or greater than the original number by a very small amount. But then you would essentially be dealing with intervals, not exact numbers.
If you break down the the entire [0, 1] interval into sub-intervals, no matter how small, you will transform the problem to one with a finite sample space. And we already know how to calculate probabilities for those.
Densities
To understand infinite sample spaces, one needs to be familiar with the concept of density. Here I’m going to define it with physical examples and later use it to explain probability densities.
In physics, the average density of an object is the total mass of the object divided by its volume. So, if you have a metal cube whose mass is 1000 kilograms and whose volume is 2 cubic meters, its average density is going to be 1000 kg / 2 m3 (or 500 kg/m3).
Because it’s easier to visualize, instead of a cube, imagine a metal rod whose mass is 1 kilogram and whose length is 1 meter. If you want to push your imagination, think of it as having no width or height… It’s simply a 1 meter long infinitely thin rod.

Because now there’s only one dimension, the average density would be measured per length, instead of per volume. So, we get:
![\[\textrm{average density} = \frac{1 kg}{1 m} = 1 kg/m\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-1e91b575ae64a3bb4bba6e18940f04f3_l3.png "Rendered by QuickLaTeX.com")
Or the general formula:
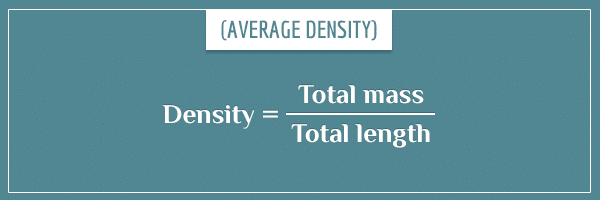
By multiplying both sides of this equation by the total length, we also get a relationship for the mass:
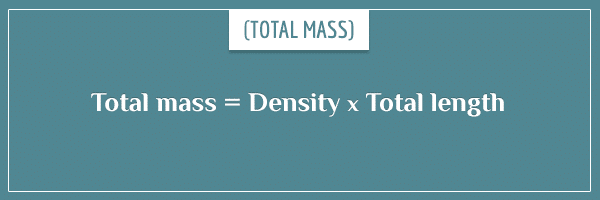
Keep this in mind, as it’s going to be very useful in a bit.
Densities at specific regions
For a moment, imagine mentally breaking down the rod into 100 equal-length pieces of 1 centimeter:
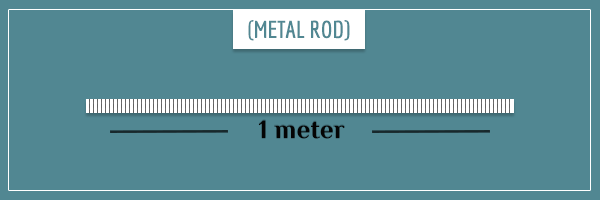
If the mass is uniformly (equally) distributed along the rod, then each of the 100 pieces will have 1/100th of the mass (10 grams). But it could also be that some pieces are more densely packed and have a higher percentage of the mass. For example, the first 20 pieces could be 25 grams each, and the remaining 80 could be 6.25 grams each.
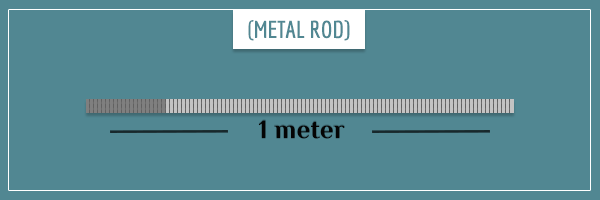
Either way, just like calculating the average density of the rod, we can calculate the density at a specific piece. For example, the density at one of the 25 gram pieces is:
![\[\textrm{density} = \frac{25 gr}{1 cm} = 25 gr/cm = 2.5 kg/m\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-5d11944b867ca2609d9a83a03491c4f4_l3.png "Rendered by QuickLaTeX.com")
Again, by using the inverse relationship, the mass of each piece is given by its length times its density. And since the mass of the entire rod is the sum of the masses of all (N number of) individual pieces, we get the following relationship:
![\[\textrm{total mass} = d_1 \cdot l_1 + d_2 \cdot l_2 + ... + d_N \cdot l_N\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-e4b6d55f4c79028786d451693a10aadf_l3.png "Rendered by QuickLaTeX.com")
Or with a more compact notation:
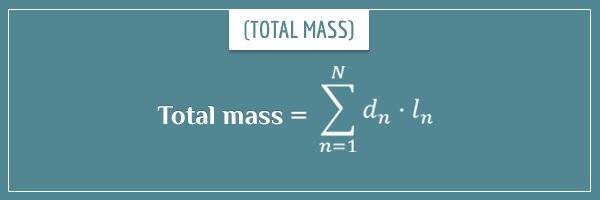
In other words, by multiplying each piece’s length by its density and summing over all pieces, you obtain the total mass of the rod. This should be pretty intuitive.
Let’s take this a step further and mentally divide the rod into even smaller pieces:
Now each piece has an even smaller fraction of the total mass and length. But we can just as easily calculate the density at any piece. Or the total mass, by summing the density*length products over all pieces.
Density at specific points
No matter how small non-overlapping pieces we break the rod into, their number is always going to be finite. But what if we break it down to points?
You will remember that points are idealized zero-dimensional objects. This means they have 0 length, height, and depth. If that’s the case, what would we get if we tried to calculate a point’s mass with the formula length*density? Multiplying any density by 0 will always give 0. Hence, summing all points’ masses will give 0 as the total mass. But we know the rod’s mass is 1 kg, so there’s clearly something wrong here.
Those of you familiar with integrals are probably already nodding with a half-smile. Unfortunately, a detailed introduction of integrals is also beyond the scope of this post, so we’ll suffice only with the general intuition.
Integrals
Integrals are closely related to the concept of limits I mentioned in the beginning. But, informally speaking, an integral is a generalization of the summation operation where you add up an infinite number of products of the form (y * dx). Here y is some value (that usually depends on x) and dx is an infinitely small interval in x. In our example, y is the density at a specific point and dx is the “length” of each point:
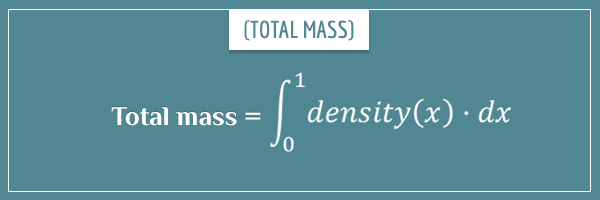
The thin S-like symbol is the integral sign. The 0 subscript and 1 superscript mean that we’re integrating (“summing”) from 0 all the way to 1 (from the first to the last point of the rod). The term density(x) represents the density at a particular point x and dx is the infinitely small interval in x I mentioned above.
Another way to think about integrals is as the area under the curve that represents the function you’re integrating. The reason is that summing all these infinite products is like adding up an infinite number of rectangles whose widths are dx and whose heights are the values of the function at each point.
The important (and counter-intuitive) thing to get out of integrals is that you end up getting a finite number by summing an infinite number of such products. Taken individually, each of the infinite terms contributes 0 by itself, but together they amount to a finite number.
If you would like to learn more about the concepts of infinitely small values, limits and integrals, there’s a great video by Numberphile I strongly recommend you watch:
And with all this in mind, let’s go back to the domain of probabilities.
Probability mass and probability density
In probability theory, the term probability mass refers to the familiar notion of probability. The entire sample space has a probability mass of 1 and the amount of probability mass of a subset of the sample space corresponds to the probability that an outcome of that subset will occur.
In infinite sample spaces, probability density is the probability mass divided by unit length of the sample space (here I’m using the term length very loosely). Similar to physical densities, probability densities can be defined at every point of the sample space.
Let’s go back to the original example of drawing a random number from the interval [0, 1]. Assuming our random number generator works properly and all numbers from the interval are equally likely to be drawn, the probability density function representing this sample space looks like this:
![The probability density function over the interval [0, 1]](https://www.probabilisticworld.com/wp-content/uploads/2017/08/probability-density-function.png)
This function gives the probability density at each point in the sample space. Notice that each point’s density is equal to 1.
A common beginner’s mistake is to read probability density functions like one would read probability mass functions. Namely, to interpret the number corresponding to a point as that point’s probability. Just from this example you can see that this interpretation is wrong: it’s certainly not true that every point has a probability of 1 of being randomly selected!
From densities to masses
To get probability mass out of a probability density, you need to multiply the latter by some interval from the sample space. As we saw in the previous section, if you take the density at any particular point and multiply it by the point’s length, you would get zero, since points don’t have length.
But we also saw that, by integrating over an interval of densities, we can obtain a non-zero mass. And from this it follows that the probability of randomly picking a point from an interval is non-zero. For example, you can say that the probability that the number is going to be between 0.34 and 0.59 is:
![\[P(x \in [0.34, 0.59]) = 0.25\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-6888745acea360bb2c2d5a718d7c1026_l3.png "Rendered by QuickLaTeX.com")
You obtain this probability mass by integrating over the probability density function from 0.34 to 0.59. As I said in the previous section, you can think of an integral as an area under a curve. In this case, the curve is a straight line. The probability that the random number is in [0.34, 0.59] is the area under that line bound between these two values. Well, that area is equal to a rectangle of height 1 and width 0.25, hence the final probability.
![The probability density function over the interval [0, 1], with shaded area](https://www.probabilisticworld.com/wp-content/uploads/2017/08/probability-density-function-with-area.png)
Bottom line is that, when dealing with infinite sample spaces, it makes sense to talk about probabilities (probability masses) only for intervals, rather than exact values. For most real-world applications, a small enough interval around an exact value could be considered identical to the value itself (for all practical purposes). But still, know that exact values always have probabilities of 0.
Almost surely and almost never
There is still some element of discomfort in the notion that zero probability outcomes occur in the world. After all, outcomes are concrete values, not intervals. And why do we say the probability is 0 if, after all, the outcome can occur?
What can we make out of the fact that something that just occurred had a probability of zero just an instant before it occurred?
Here the probability theory notions of almost surely and almost never come to the rescue. An event happens almost surely if it has a probability of 1. And it happens almost never if it has a probability of zero. The “almost” is there precisely to acknowledge the fact that, in infinite sample spaces, 0 doesn’t imply impossibility and 1 doesn’t imply absolute certainty. It implies that, for all practical purposes, in any individual “trial”, a zero probability event will not happen and an event with probability 1 will always happen.
I focused most of my attention to “almost never” events. But “almost surely” events are very similar. For example, if you exclude any specific number from the set [0, 1], the probability of drawing a number from the newly created set is 1, even though it’s still theoretically possible to draw exactly the excluded number. As you can see, the two notions are tightly connected.
Summary
Unless you decide to specialize in certain theoretical fields, this post doesn’t have too many practical implications for whatever purposes you have in life. My main goal was to give an intuitive explanation for the curious cases of possible events that have zero probabilities and events with probabilities of 1 that may still not happen.
Here are the main take-home points:
- In finite sample spaces, zero probability events are impossible and impossible events have zero probabilities.
- Impossible events have zero probabilities AND zero probability densities in infinite sample spaces.
- In infinite sample spaces, a probability of 0 by itself doesn’t imply an event is impossible to happen. It implies it will happen almost never.
- In infinite sample spaces, a probability of 1 by itself doesn’t imply an event will happen with absolute certainty. It implies it will happen almost surely.
I also gave a short introduction on probability masses and probability densities and their relationship through integration, in order to give the intuitive reasons why the 4 statements above are true. These concepts are extremely useful in virtually all fields that use probabilities, not just for explaining curious cases like the ones here. If you have more clarity on them now than before you read this post, then you have gained valuable insights in probability theory you will find helpful while trying to understand more complicated concepts.
When dealing with probability densities, all specific values have probabilities of 0. But the same values can have small, large, or very large densities behind them. Hence, even though two values can both have a probability of 0, one of them (or values in its close vicinity) could still be more likely to actually occur. Not all zero probabilities are created equal!
Dear sir,
Thank you very much for your post. I don’t understand why the density function is equal to 1 (density(x) = 1)
Hi Tuan, thanks for writing!
The density function isn’t necessarily equal to 1. In fact, most of the time it isn’t. The “sum” (integral) of all probability densities is equal to 1 because the sample space must have a probability equal to one. Does this partly answer your question?
I’m not entirely sure which part of the post you’re referring to. Could you cite the paragraph you’re struggling to understand?
Thanks for writing this! My curious train of thought led me here. I’m enjoying an iced long black in a cafe in Brisbane, Australia, trying to workout the probability of my existence in this exact circumstance. Logically I thought it must be 1 in infinity, which is impossible… but yet I am here. Then it occurred to me that not only the probability of my existence in my current form is impossible, literally everything that happened, in the way that it happened, ever since the beginning of the universe is impossible. I guess the answer is that the chance of any real life event is ‘almost never’, because any real life event is comparable to an ‘exact value’ (which has a probability of zero), but in our infinite universe, it could happen.
I have to agree with your final assessment, Niam. Any real life event’s probability is indeed “zero” in the sense of “almost never”.
That long black has pushed you to some deep (and very interesting!) existential questions 🙂
Niam,
I think we need to talk this over. I have been trying to work out the probability of my existence most of my life. My conclusions have always been 0 or almost 0, yet, here I am. How is this possible????
Amazing clarity, precision, and grammar 🙂 as always.
Thank you
Thank you, Laurie! And thanks for the warm and positive feedback you gave me through other channels! I am very happy that you are benefiting from my posts.
Thank-you for writing an extremely clear article. However, there is still something that puzzles me. Suppose we consider all real numbers between 0 and 1. It would seem the probability of choosing some random number m between 0 and 1 is zero. Let’s write Pr(m) = 0. Similarly the probability of choosing some other random number n is zero. Pr(n = 0. But what are to say about the probability of choosing either n or m? Intuitively, this would still be zero because (roughly) “2 divided by infinity is still zero”. Also, if we accept Pr(m or n) = Pr(m) + Pr(n), then Pr(m or n) = 0 + 0 = 0. So, it seems Pr(m or n) = 0. But it seems we also want to say that the probability of choosing m or n is greater than the probability of choosing m. We might even feel inclined to say it is twice as great. What are we to say here? Are we to say that actually Pr(m or n) = Pr(m), even though this might seem odd?