
In today’s (relatively) short post, I want to show you the formal proofs for the mean and variance of discrete uniform distributions. I already talked about this distribution in my introductory post for the series on discrete probability distributions. Well, this is a pretty simple type of distribution that doesn’t really need its own post, so I decided to make a post that specifically focuses on these proofs. More than anything, this is going to be a small exercise in algebra.
This post is part of my series on discrete probability distributions.
In short, you use the discrete uniform distribution when you have n possible outcomes that are equally likely to occur. That is, when the sample space you’re interested in consists of exactly n elements, each of which occupy an equal share of the whole space. Before we look at the mean and variance formulas and their proofs, let’s review (and somewhat generalize) the discrete uniform distribution’s probability mass function (PMF).
Table of Contents
Discrete uniform distribution and its PMF
So, for a uniform distribution with parameter n, we write the probability mass function as follows:

Here x is one of the natural numbers in the range 0 to n – 1, the argument you pass to the PMF. And n is the parameter whose value specifies the exact distribution (from the uniform distributions family) we’re dealing with. Specifically, the number of possible outcomes. You remember the semi-colon notation for separating parameters (and what parameters are), right? If not, it might be a good idea to review the intro post.
For example, when n = 8, we can plot the probabilities of  of the numbers 0 through 7:
of the numbers 0 through 7:
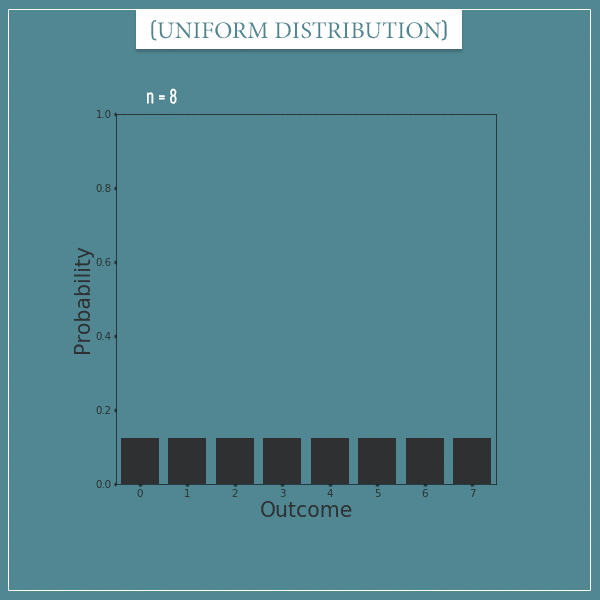
Notice that this distribution doesn’t simply model outcomes which happen to be equally likely. The numbers have to be consecutive! If they aren’t, it would be more appropriate to model the process with a categorical distribution.
In the intro post, I showed you the uniform distribution’s canonical version where the first number is always 0. But, as long as we keep the numbers consecutive, we can shift the distribution to the left or to the right. For example, here’s the same distribution shifted 4 numbers to the right:
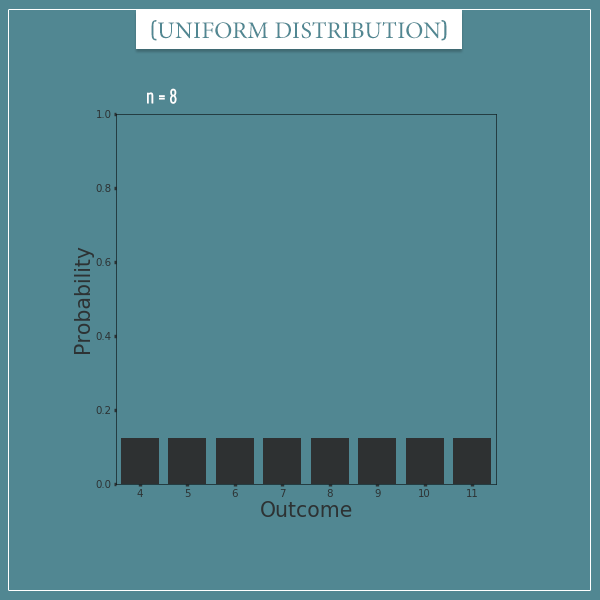
If we’re dealing with a shifted distribution, we need to specify an additional parameter for the starting value. Today I want to use the letter L (for “lower bound“) for this parameter:

Notice that the canonical version is a special case of this more general version with L = 0.
Yet a third way to parameterize this distribution is by also specifying the upper bound parameter U:

Notice that specifying L and U automatically determines n because:
![\[n = U - L + 1\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-a2f3d7db06f3be889d15e6513b7db97a_l3.png "Rendered by QuickLaTeX.com")
In the example above,
 ,
,  , and
, and  .
.
For another example, consider the distribution with parameters  and
and  with which you can model the probability of the pocket the ball will land in for a particular roulette spin.
with which you can model the probability of the pocket the ball will land in for a particular roulette spin.
Mean and variance formulas
So, here I’m going to give you the standard formulas for the mean and variance of a uniform distribution with parameters n or L and U. I’m going to use  (the Greek letter mu) for the mean and
(the Greek letter mu) for the mean and  (the Greek letter sigma squared) for the variance.
(the Greek letter sigma squared) for the variance.
Those are the most common notations for these two measures. In particular, is based on  , which is how standard deviation is typically denoted. You remember the relationship between variance and standard deviation from my introductory post on measures of dispersion, right?
, which is how standard deviation is typically denoted. You remember the relationship between variance and standard deviation from my introductory post on measures of dispersion, right?
Anyway, here are the two formulas for the canonical version of the distribution:
![\[\mu = \frac{n-1}{2}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-015ad7dd84e6838116ac0ffaece82e30_l3.png "Rendered by QuickLaTeX.com")
![\[\sigma^2 = \frac{n^2 - 1}{12} \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-a3eff3eb4ced12810eab736041fb957e_l3.png "Rendered by QuickLaTeX.com")
The variance formula for the more general (shifted) version is the same as the one above. On the other hand, the mean formula has a small modification:
![\[\mu = \frac{n-1}{2} + L\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-58a367c0953687da50c373afb4b14889_l3.png "Rendered by QuickLaTeX.com")
That is, we simply add the lower bound parameter L to the canonical mean, again with the understanding that
 .
.
Proofs of mean and variance formulas
Before I show you the proofs, I’m want to list a few properties and identities we’re going to need to understand them. The first two concern the mean and variance of an arbitrary shifted distribution:
![\[\mu(X + c) = \mu(X) + c\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-51bd7607403e8f047dc9bc7c769a75cc_l3.png "Rendered by QuickLaTeX.com")
![\[\sigma^2(X + c) = \sigma^2(X)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-34db1bf1c475dbd9a91966fba0e4bcda_l3.png "Rendered by QuickLaTeX.com")
What these identities say is that shifting an arbitrary random variable by adding an arbitrary constant c to all of its possible values has the following effect on the mean and variance:
- The mean gets shifted by c
- The variance remains the same
Since I haven’t talked about these properties before, I’m going to show you their proofs in the bonus section at the end of this post. For now, just take my word for it. These two properties will allow us to easily generalize the mean and variance formulas from the canonical version of a uniform distribution to its general (arbitrarily shifted) form.
And here’s the remaining properties and identities we’re going to need.
Auxiliary properties and identities
First, you should feel comfortable with properties of arithmetic operations. In particular the familiar commutative and associative properties of addition and multiplication, as well as the distributive property of multiplication over addition. All these properties state that, for arbitrary numbers a, b, and c:
![\[a + b = b + a\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-51a683e80b53b22991a162969211cff9_l3.png "Rendered by QuickLaTeX.com")
![\[a \cdot b = b \cdot a\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-aa6b329dfae221cccd9980c9f2f5e3fc_l3.png "Rendered by QuickLaTeX.com")
![\[a + (b + c) = (a + b) + c\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-f76d2e077675e729a2133104eca91510_l3.png "Rendered by QuickLaTeX.com")
![\[a \cdot (b \cdot c) = (a \cdot b) \cdot c\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-8dac08ce3b0fca94f6da428e23c326bb_l3.png "Rendered by QuickLaTeX.com")
![\[a \cdot (b + c) = a\cdot b + a \cdot c\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-126e54f7562cfd0f8a6e6d7c13ba22e6_l3.png "Rendered by QuickLaTeX.com")
Second, we’re going to rely on the following two properties of the sum operator (derived from the arithmetic properties above):
(1) 
(2) 
Third, we’re going to need the following closed-form formulas (which I also talked about in the sum operator post):
(3) 
(4) ![\begin{equation*} \sum_{i=0}^{n} i^2 = \frac{n(n+1)(2n+1)}{6}\] \end{equation*}](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-28349abe1a5681bbb35116c330d6d1a1_l3.png "Rendered by QuickLaTeX.com")
Finally, we’re going to need the following alternative variance formula of a random variable X:
(5) ![\begin{equation*} \sigma^2(X)} = \mathop{\mathbb{E}[X^2] - \mathbb{E}[X]^2 \end{equation*}](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-3f48d9272649f18434d463498ee97dd4_l3.png "Rendered by QuickLaTeX.com")
Where
![\mathbb{E}[.]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-56778195896d7ea54075d1abc01e0a14_l3.png "Rendered by QuickLaTeX.com") is the expected value notation.
is the expected value notation.
If all these properties (and notation) are new to you, I recommend you review the posts I linked to so far, where you’ll find everything explained in detail.
And with all that out of the way, let’s finally get to the proofs we’re interested in!
The mean
To calculate the mean of a discrete uniform distribution, we just need to plug its PMF into the general expected value notation:
![\[\sum_{i=0}^{n-1} x_i \cdot P(x_i) = \sum_{i=0}^{n-1} i \cdot \frac{1}{n}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-72b8e6e246cc9b48d6ed529da0f6bf3b_l3.png "Rendered by QuickLaTeX.com")
Then, we can take the
 factor outside of the sum using equation (1):
factor outside of the sum using equation (1): ![\[\sum_{i=0}^{n-1} i \cdot \frac{1}{n} = \frac{1}{n} \cdot \sum_{i=0}^{n-1} i\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-3c053c25e089b61d57ff98007f50e7e9_l3.png "Rendered by QuickLaTeX.com")
Finally, we can replace the sum with its closed-form version using equation (3):
![\[\frac{1}{n} \cdot \sum_{i=0}^{n-1} i = \frac{1}{n} \cdot \frac{n(n-1)}{2}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-535329af28bb9ed9ad38af7f8dfbc6b0_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{n-1}{2}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-bc87fe938d16583e9b8c170bd80fb7ac_l3.png "Rendered by QuickLaTeX.com")
And there you have it, we just derived the mean formula I showed you in the previous section!

Notice that we slightly modified the closed-form expression for the sum with the following substitutions:


That is because in our case the sum runs from 0 to n – 1, instead of from 0 to n (as in equation (3)).
Were you expecting a more complicated proof? Well, maybe not.
So, this is the mean formula for the canonical version whose lower bound L is 0. Using the mean of a shifted distribution identity I gave above, we can generalize the mean for any lower bound L:
![\[\mu(X) = \frac{n-1}{2} + L\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-f79e395fa652411b6367678b8621de3a_l3.png "Rendered by QuickLaTeX.com")
To get more intuition about this formula, let’s add the two terms and replace n with
 :
: ![\[\mu(X) = \frac{n-1}{2} + \frac{2L}{2}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-10bf005d8579b734a779374cefe23e94_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{n-1 + 2L}{2}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-5dd65b5b60a63306587419e6809a2da1_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{(U - L + 1) - 1 + 2L}{2}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-9dfb84abefa48d166d75a85f30d2bd0a_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{L + U}{2}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-33647ad186438ab5ef0afce1ee59f840_l3.png "Rendered by QuickLaTeX.com")
You’ll commonly see this version of the formula, which shows that the mean of the distribution is nothing but the arithmetic mean of the lower and upper bounds!
The variance
Now let’s do the derivation for the variance of a discrete uniform distribution formula. We’re going to use the alternative variance formula from equation (5):
![\[\sigma^2(X)} = \mathop{\mathbb{E}[X^2] - \mathbb{E}[X]^2\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-4f61f9c743d0fa07faf92e8d27bf1bf6_l3.png "Rendered by QuickLaTeX.com")
Let’s start with the second term because it’s easier. This is simply the square of the mean we just derived:
![\[\mathbb{E}[X]^2 = \left(\frac{n-1}{2}\right)^2\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-e270f463ddb1e5d35be068dec9479e4c_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{(n-1)^2}{4}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-9d81f3db0568aeafabce8eb5b636f334_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{n^2 - 2n + 1}{4}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-6d7136775d9fdc64351792aa2f0dc2b9_l3.png "Rendered by QuickLaTeX.com")
Now let’s focus on the second term by first taking the
out using equation (1): ![\[\mathop{\mathbb{E}[X^2] = \sum_{i=0}^{n-1} i^2 \frac{1}{n}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-46daea0c1b9259b1d611cc23ecb2aa4f_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{1}{n} \sum_{i=0}^{n-1} i^2\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-ade5c55cff4b36787ed2e2b6281f310f_l3.png "Rendered by QuickLaTeX.com")
Then, we can substitute the sum with the right-hand side of equation (4) and simplify:
![\[\frac{1}{n} \sum_{i=0}^{n-1} i^2= \frac{1}{n} \frac{n(n-1)(2n-1)}{6}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-19f7bc7c39c95dd120cc82db0fedcc1f_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{(n-1)(2n-1)}{6}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-fce05c06b3a6135b936abf42e2e5e8ba_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{2n^2 - 3n + 1}{6}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-553fe18a608316fdb0cabfbd323be295_l3.png "Rendered by QuickLaTeX.com")
So, now that we have simple expressions for the two terms, we can plug them into equation (5) and do the final simplification:
![\[\sigma^2(X) = \mathop{\mathbb{E}[X^2] - \mathbb{E}[X]^2 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-d9ce3ef42bf67241b01823bcade369d3_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{2n^2 - 3n + 1}{6} - \frac{n^2 - 2n + 1}{4}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-c0786bc890b131e6dfcf237566d6cbab_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{4n^2 - 6n + 2}{12} - \frac{3n^2 - 6n + 3}{12}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-fe5d638d91b971983766dd3a96e882ce_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{4n^2 - 6n + 2 - 3n^2 + 6n - 3}{12} \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-149521e19a240ba4b1df6756c4fdd8d1_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{n^2 - 1}{12} \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-557fc537b5737f89b7fe6129b80d3435_l3.png "Rendered by QuickLaTeX.com")
And we reached the expected result!
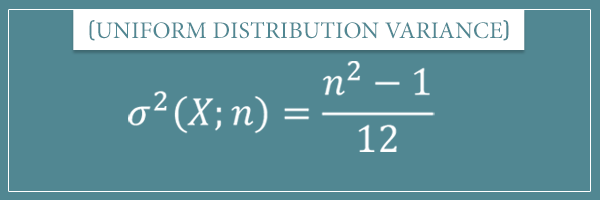
See how easy these proofs are when we already have the proper tools at hand?
And since shifting a random variable doesn’t change its variance, this is also the formula for the general discrete uniform distribution.
You could also express the formula in terms of L and U:
![\[\sigma^2(X) = \frac{(U - L + 1)^2 - 1}{12}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-a13378643c0f2a79b5512c4be2ca61c7_l3.png "Rendered by QuickLaTeX.com")
![\[= \frac{L^2 + U^2 + 2(U - L - LU)}{12}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-fa40c85fb1f19986aa483ea673ffc373_l3.png "Rendered by QuickLaTeX.com")
Though the representation in terms of n is definitely more elegant (and preferable)!
Summary
Well, this is it for today. The discrete uniform distribution is one of the simplest distributions and so are the proofs of its mean and variance formulas.
The special and general probability mass functions of this distribution look like this:
![\[P(x; n) = \frac{1}{n}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-6fb689750d175d91680dfd252d823bd5_l3.png "Rendered by QuickLaTeX.com")
![\[P(x; L, U) = \frac{1}{U - L + 1}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-6c5357dd4c1953fbb4c11d7ef022ea99_l3.png "Rendered by QuickLaTeX.com")
And the mean and variance formulas whose derivation I showed you are:
![\[\mu(X) = \frac{n-1}{2}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-9ee8d5c5e7b274c4a9d4006173cc8379_l3.png "Rendered by QuickLaTeX.com")
![\[\sigma^2(X) = \frac{n^2 - 1}{12}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-48c49179046b151be8e0950888482432_l3.png "Rendered by QuickLaTeX.com")
The general variance formula looks exactly the same, whereas the general mean formula takes a small modification:
![\[\mu(X) = \frac{n-1}{2} + L = \frac{L + U}{2}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-42c0c3c7b15e494b53d4dfd01d3d5c64_l3.png "Rendered by QuickLaTeX.com")
Anyway, if you had any issues with following the derivations, don’t hesitate to ask your questions in the comment section below!
Now, as I promised, for the curious among you I’m going to show the proofs for the mean and variance identities regarding shifted random variables.
Bonus section

As you saw, the proofs for the mean and variance of discrete distributions are very short and easy to follow. Well, this is also because we had other (previously proved) identities at our disposal.
On the other hand, the direct proofs of the general version of the distribution are a bit hairy. For that reason, in this bonus section I want to show you the proofs of two general facts about the mean and variance of an arbitrary shifted discrete distribution. These were the facts that allowed us to immediately adapt the special case proofs to the general case (and circumvent the hairy direct proofs).
Basically, to shift a distribution simply means adding an arbitrary constant c to every value of the sample space. In the example in the beginning, we shifted the canonical uniform distribution (with parameter n = 8) 4 numbers to the right by adding the constant c = 4 to every value in the range 0 to 7 (and the new range became 4 to 11).
Now let’s see what happens to the mean and variance of any discrete distribution, not just the one we’re currently looking at.
Mean of a shifted random variable
As a reminder, here’s the general formula for the expected value (mean) a random variable X with an arbitrary distribution:
![\[\mathbb{E}[X] = \mu(X) = \sum_{i} x_i p(x_i)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-9133171f02b21a8968d55cd613d542bc_l3.png "Rendered by QuickLaTeX.com")
Notice that I omitted the lower and upper bounds of the sum because they don’t matter for what I’m about to show you. Assume that the sum ranges over all values in the sample space.
Now let’s create a new random variable Y which is the shifted version of X by an arbitrary constant c:
![\[Y = X + c\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-5430ae8108f85be5037d06e195632785_l3.png "Rendered by QuickLaTeX.com")
And let’s write an expression for its mean:
![\[\mathbb{E}[Y] = \mathbb{E}[X + c] = \mu(X + c) = \sum_{i} (x_i + c) p(x_i)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-f4d00d56afeb1f7f3867017e89b17737_l3.png "Rendered by QuickLaTeX.com")
Now, using the commutative and distributive properties of multiplication, as well as identities (1) and (2) from above, we can rewrite the right-hand side as follows:
![\[\sum_{i} (x_i + c) p(x_i) = \sum_{i} \left(x_i p(x_i) + c p(x_i)\right) \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-9ed8baddb27a4ad57b2c77c2a6fb99f9_l3.png "Rendered by QuickLaTeX.com")
![\[= \sum_{i} x_i p(x_i) + \sum_{i} c p(x_i)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-3418fe2984ec941cc0491e13c25f3b70_l3.png "Rendered by QuickLaTeX.com")
![\[= \mu(X) + c\sum_{i} p(x_i)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-b9bd443c434a18dc271ce0b0b514d6ec_l3.png "Rendered by QuickLaTeX.com")
![\[= \mu(X) + c\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-3caacae67cd11b71dc2accfad333ed59_l3.png "Rendered by QuickLaTeX.com")
In the third line, we replaced
 with
with  and in the fourth line we replaced
and in the fourth line we replaced  with 1 because the sum of all elements in the sample space is always equal to 1. Therefore, the mean of a random variable shifted by c is simply the mean of the unshifted version itself shifted by c:
with 1 because the sum of all elements in the sample space is always equal to 1. Therefore, the mean of a random variable shifted by c is simply the mean of the unshifted version itself shifted by c:
Cool. Now let’s see how things work with the variance.
Variance of a shifted random variable
As a reminder, here’s the canonical variance formula:
![\[\sigma^2(X) = \sum_{i} (x_i - \mu(X))^2 p(x_i)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-75be4452ca7581e00a8d5d9947fe704e_l3.png "Rendered by QuickLaTeX.com")
Now, let’s apply it on the shifted version of X:
![\[\sigma^2(X + c) = \sum_{i} \left[(x_i + c) - \mu(X+c)\right]^2 p(x_i)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-1539fedb4e5cc46320486cd8ecb45e8a_l3.png "Rendered by QuickLaTeX.com")
![\[= \sum_{i} \left[(x_i + c) - (\mu(X) + c)\right]^2 p(x_i)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-85d424e4f978aa1bdc9837f0a5f8a022_l3.png "Rendered by QuickLaTeX.com")
![\[=\sum_{i} (x_i + c - \mu(X) - c)^2 p(x_i)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-8004842cf1ff1e1be9bc2147f364e2c2_l3.png "Rendered by QuickLaTeX.com")
![\[= \sum_{i} (x_i - \mu(X))^2 p(x_i) = \sigma^2(X)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-56104406844685321d1ddf14f481b944_l3.png "Rendered by QuickLaTeX.com")
In the second line I simply replaced
 with
with  (which we just derived). And in the third line I simply expanded the inner parentheses. The net result is that the constant c got cancelled out and we’re left with the original expression. Which means that shifting a random variable doesn’t change its variance!
(which we just derived). And in the third line I simply expanded the inner parentheses. The net result is that the constant c got cancelled out and we’re left with the original expression. Which means that shifting a random variable doesn’t change its variance!
And by the way, in case you’re wondering, the same identities hold true for the mean and variance of a continuous random variable. But I’ll leave those proofs for a future post (after I’ve introduced a bit of calculus).
Would be great to touch upon real-time/continuous calculaiton of mean and – especially – variance/std.