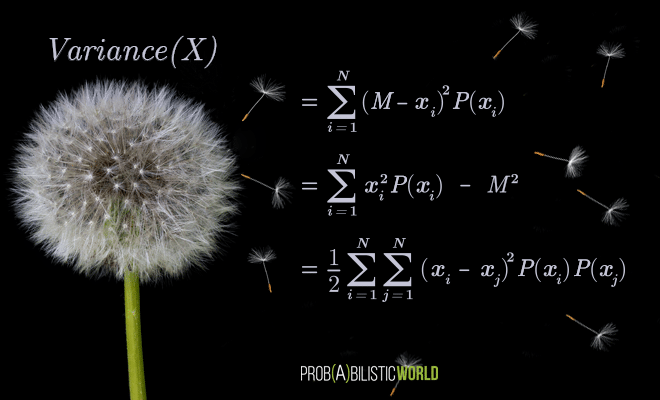
In today’s post I want to show you two alternative variance formulas to the main formula you’re used to seeing (both on this website and in other introductory texts).
Not only do these alternative formulas come in handy for the derivation of certain proofs and identities involving variance, they also further enrich our intuitive understanding of variance as a measure of dispersion for a finite population or a probability distribution.
I also want to use this post as an exercise for performing useful manipulations of expressions involving the sum operator. This mathematical notation and its properties was the topic of my last post and today I want to show you real examples of how you can apply thеse properties in certain derivations.
As a quick reminder, the sum operator is a mathematical notation for expressing sums of elements of a sequence.
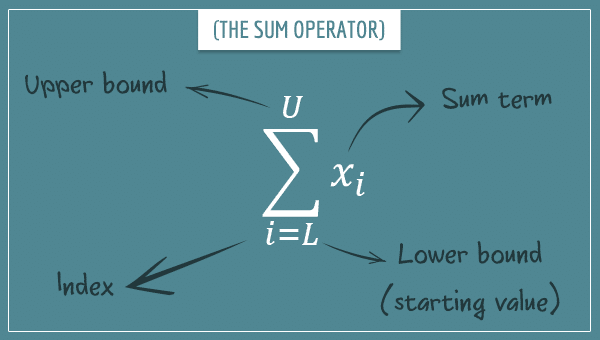
You expand such expressions by iterating over the values of the index i between the lower and the upper bound, plugging each value into the sum term and adding it to the existing sum:
![\[\sum_{i=L}^{U} x_i = x_{L} + x_{L+1} + ... + x_{U}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-b4d946a81f4be9e1d5cb15758f066f4c_l3.png "Rendered by QuickLaTeX.com")
Before I move to the actual alternative formulas, I want to give a quick review of some properties and formulas I’ve derived in previous posts.
Table of Contents
Overview of sum operator and variance formulas
In deriving the alternative variance formulas, I’m going to use the following four sum operator properties. I wrote them as labeled equations so that I can easily refer to them later on:
Multiplying a sum by a constant:
(1) 
Adding or subtracting sums with the same number of terms:
(2) 
Multiplying sums:
(3) 
Changing the order of double sums:
(4) 
As far as variance is concerned, I first talked about it in my post about the different measures of dispersion in the context of finite populations. The formula I showed you in that post was:
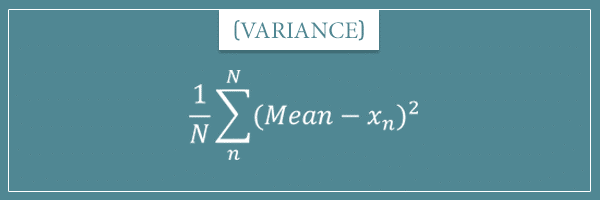
And in my post about the mean and variance of probability distributions I showed you the following formula for discrete probability distributions:
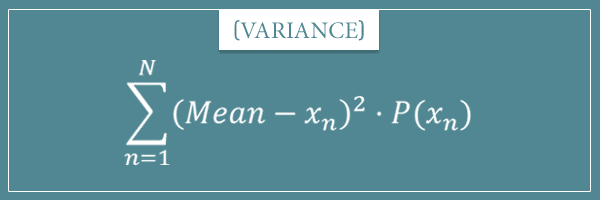
As well as this formula for continuous probability distributions:
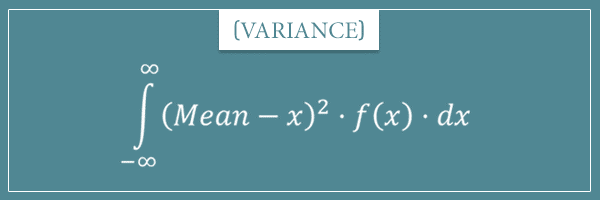
I’m first going to derive the alternative formulas for discrete probability distributions and after that I’m going to show you their finite population and continuous distribution counterparts.
By the way, notice that I used n instead of i as the index variable in the images above. In other posts I’ve also used the letter k. Obviously the choice of letter doesn’t matter, but for the rest of this post I’m going to stick to the convention of using i for the index (as well as j, when we’re dealing with double sums).
Other background information
Besides these properties and formulas, I’m also generally going to rely on the properties of arithmetic operations. If you’re not familiar with them, check out my post on the topic.
It’s probably also useful to get familiar with the concept of expected value (if you’re not already), which you can do by reading my introductory post on expected value. In parts of this post I’m going to use one of the notations I showed you there. Namely, for a random variable X, the expected value (or mean) of the variable is expressed as:
(5) ![\begin{equation*}\mathop{\mathbb{E}[X] = \sum_{i=1}^{N} x_i \cdot P(x_i)\end{equation*}](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-5bf7efe7fdfda425adee6ccd16aebffe_l3.png "Rendered by QuickLaTeX.com")
That is, with the capitalized and blackboard bold version of the letter E.
Oh, and one last thing. In the derivations below, I’m occasionally going to make use of a special case of the binomial theorem (which I explained in my post on the binomial distribution). Namely, the following identity which holds true for any two real numbers x and y:
(6) 
And, with all this in mind, let’s finally get to the meat of today’s topic.
Alternative variance formula #1
For those of you following my posts, I already used this formula in the derivation of the variance formula of the binomial distribution. Here it is:
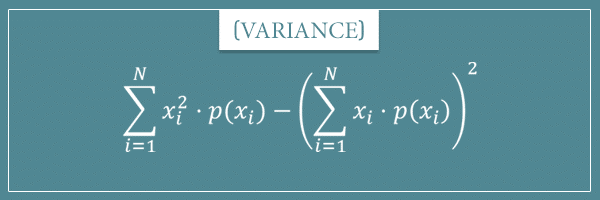
In words, it says that the variance of a random variable X is equal to the expected value of the square of the variable minus the square of its mean. Let’s first prove that this formula is identical to the original one and then I’m going to briefly discuss it.
If you’re confused by what the expected value of  means, take a look at this section from my post on mean and variance of probability distributions.
means, take a look at this section from my post on mean and variance of probability distributions.
Derivation
Let’s start with the general formula for the variance of a discrete probability distribution where we write M for the mean:
![\[ \textrm{Variance(X)} = \sum_{i=1}^{N} (M - x_i)^2 \cdot P(x_i) \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-e79cdaad247db15f5f0314bdbebe6b75_l3.png "Rendered by QuickLaTeX.com")
First, using equation (6), let’s expand the squared difference inside the sum:
![\[ (M - x_i)^2 = M^2 - 2Mx_i + x_i^2 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-5eb4490646956b27c00704166c3f2700_l3.png "Rendered by QuickLaTeX.com")
Then we can rewrite the variance formula as:
![\[ \textrm{Variance(X)} = \sum_{i=1}^{N} (M^2 - 2Mx_i + x_i^2) \cdot P(x_i) \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-b6ce00409a2b939bf9dbde89804d6533_l3.png "Rendered by QuickLaTeX.com")
![\[ = \sum_{i=1}^{N} \left( M^2 \cdot P(x_i) - 2Mx_i \cdot P(x_i) + x_i^2 \cdot P(x_i) \right) \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-fd99a4308e444a40525f17bff7490f77_l3.png "Rendered by QuickLaTeX.com")
In the last line, I simply used the distributive property of multiplication over addition to put the
 inside the parentheses.
inside the parentheses.
Splitting the big sum into simpler sums
Now, using equation (2), we can rewrite the above formula as:
![\[\textrm{Variance(X)} = \sum_{i=1}^{N} \left( M^2 \cdot P(x_i) - 2Mx_i \cdot P(x_i) + x_i^2 \cdot P(x_i) \right) \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-0de1cec32542cad4f6e2989882aada4c_l3.png "Rendered by QuickLaTeX.com")
![\[ = \sum_{i=1}^{N} M^2 \cdot P(x_i) - \sum_{i=1}^{N} 2Mx_i \cdot P(x_i) + \sum_{i=1}^{N} x_i^2 \cdot P(x_i) \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-aec2709f765313d82807a54568a57be0_l3.png "Rendered by QuickLaTeX.com")
Finally, using equation (1), we can take out the constant terms outside the sums and rewrite this as:
![\[ M^2 \cdot \sum_{i=1}^{N} P(x_i) - 2M \cdot \sum_{i=1}^{N} x_i \cdot P(x_i) + \sum_{i=1}^{N} x_i^2 \cdot P(x_i) \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-6696c314e6fa256a05746f10d362d890_l3.png "Rendered by QuickLaTeX.com")
Notice that:
![\[ \sum_{i=1}^{N} P(x_i) = 1 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-3bd3046ec92857c74ae7498c0540459a_l3.png "Rendered by QuickLaTeX.com")
Because this is the sum of probabilities of all possible values (which by definition is equal to 1). Furthermore:
![\[ \sum_{i=1}^{N} x_i \cdot P(x_i) = M \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-49e339eb976535c9b16aeb2d98c7ff76_l3.png "Rendered by QuickLaTeX.com")
Which is simply the mean of the distribution from equation (5)!
Finally:
![\[\sum_{i=1}^{N} x_i^2 \cdot P(x_i) = \mathbb{E}[X^2]\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-fc092478e4d0ad83855dd966de3ab769_l3.png "Rendered by QuickLaTeX.com")
Which is simply the expected value of
.
Final steps
Plugging these three into the full expression for the variance formula, we get:
![\[ \textrm{Variance(X)} = M^2 \cdot 1 - 2M \cdot M + \mathop{\mathbb{E}[X^2] \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-d0d9c71f9ce4d826e109920c7d833ef6_l3.png "Rendered by QuickLaTeX.com")
![\[ = M^2 - 2M^2 + \mathop{\mathbb{E}[X^2] \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-2e8cdfdd541ad678fafd5879c86e89ec_l3.png "Rendered by QuickLaTeX.com")
And adding the
 terms:
terms: ![\[\textrm{Variance(X)} = \mathop{\mathbb{E}[X^2] - M^2 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-76aee13957aa9a56236f7fe8af017923_l3.png "Rendered by QuickLaTeX.com")
![\[ = \mathop{\mathbb{E}[X^2] - \mathop{\mathbb{E}[X]^2 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-ab2905fd1abf4aa1085810aa2eca24e4_l3.png "Rendered by QuickLaTeX.com")
The last two expressions are identical. In various articles you’ll typically see the second one and, admittedly, it looks more elegant. But I personally prefer the first one because I find it a bit more readable.
And we’re done! Now we can finally state the following with confidence:
![\[ \textrm{Variance(X)} = \sum_{i=1}^{N} (M - x_i)^2 \cdot P(x_i) = \mathop{\mathbb{E}[X^2] - M^2 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-8a8e9b8e542dcb3f4193e1dffb63713c_l3.png "Rendered by QuickLaTeX.com")
Discussion
In my first post on variance, I told you that any measure of dispersion needs to be a number between 0 and infinity (∞). Furthermore, a measure has to be sensitive to how much the data is spread. It should be 0 if and only if there is absolutely no variability in the data and it should grow as the data becomes more spread (or dispersed).
The main formula of variance is consistent with these requirements because it sums over squared differences between each value and the mean. If all values are equal to some constant c, the mean will be equal to c as well and all squared differences will be equal to 0 (hence the variance will be 0). And as the values get farther from the mean, the square of their deviations also grows.
Random variables with zero mean
To understand the intuition behind the first alternative variance formula, imagine a random variable whose mean is equal to 0. Let’s denote it as  . Quick question: what is the variance of ?
. Quick question: what is the variance of ?
Well, if the mean is zero, by definition ![\mathbb{E}[X_o] = 0](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-bd5d95a4903511deb5253a40ba4d573d_l3.png "Rendered by QuickLaTeX.com") and the alternative formula reduces to:
and the alternative formula reduces to:
![\[\textrm{Variance(}X_o\textrm{)} = \mathop{\mathbb{E}[X_o^2] - \mathbb{E}[X_o]^2 = \mathop{\mathbb{E}[X_o^2] - 0^2\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-62d7acf3f6f7e746d227e595fe8f93cd_l3.png "Rendered by QuickLaTeX.com")
![\[= \mathop{\mathbb{E}[X_o^2]\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-b7a4294588678d0cbe7b7b0c5c07341e_l3.png "Rendered by QuickLaTeX.com")
Actually, the main formula would reduce to the same thing as well but the point is that, if the mean is 0, the variance simply measures the expected squared deviations from 0. The farther apart the values are from 0, the bigger their spread. And, hence, the larger the variance will be. So far, it’s intuitive enough.
Adding a constant to a zero-mean variable
Now let’s create a new random variable by adding some constant M to :
![\[Y = X_o + M\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-7542e47fd204968706784f84e67a7ef3_l3.png "Rendered by QuickLaTeX.com")
Notice that the mean of this new random variable is going to be M (this should be pretty intuitive, but try to prove it as an exercise):
![\[\mathop{\mathbb{E}[Y] = \mathop{\mathbb{E}[X_o + M] = M\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-32f7fd98eb109f181cef088a520bd6ca_l3.png "Rendered by QuickLaTeX.com")
But since we’re adding a constant, we’re simply shifting the distribution to the left or to the right (depending on whether the constant is a positive or a negative number). We’re not actually changing its variability in any way, which means that its variance should remain the same:
![\[\textrm{Variance(}X_o + M\textrm{)} = \textrm{Variance(}X_o\textrm{)}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-39e17620ea69f9e9c8f023db0cb39c72_l3.png "Rendered by QuickLaTeX.com")
This is indeed a property of variance that can be easily proved, which I’ll do in a future post (along with other properties). Though feel free to try it yourself as an exercise.
Now let’s write an expression for the variance of Y:
![\[\textrm{Variance(Y)} = \textrm{Variance(}X_o + M\textrm{)} = \mathop{\mathbb{E}[(X_o + M)^2] - \mathop{\mathbb{E}[X_o + M]^2\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-ac506c9b260c3fcf7a458acc01097332_l3.png "Rendered by QuickLaTeX.com")
![\[= \mathop{\mathbb{E}[(X_o + M)^2] - M^2\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-76c5329eb66d1735522754d92ba02644_l3.png "Rendered by QuickLaTeX.com")
And since we know that the variance of
 should be equal to
should be equal to ![\mathop{\mathbb{E}[X_o^2]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-c1e6729ea006f20ec6266d3ef113b3e0_l3.png "Rendered by QuickLaTeX.com") :
: ![\[\textrm{Variance(Y)} = \mathop{\mathbb{E}[(X_o + M)^2] - M^2 = \mathop{\mathbb{E}[X_o^2]\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-0627e994a47e2f1cbb4b064c44d71862_l3.png "Rendered by QuickLaTeX.com")
From which it follows that:
![\[\mathop{\mathbb{E}[(X_o +M)^2] = \mathop{\mathbb{E}[X_o^2] + M^2\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-41518b9775be0fbdb1cd101afe022c28_l3.png "Rendered by QuickLaTeX.com")
That is, this line of reasoning lead us to the conclusion that adding a constant M to a random variable whose mean is 0 is the same as adding
to the expected value of the square of the variable. To complete our mathematical intuition, let’s prove this independently: ![\[\mathop{\mathbb{E}[(X_o +M)^2] = \mathop{\mathbb{E}[(X_o^2 +2X_oM + M^2)]\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-8e157520d9465cb4dd3d0a043257ddd7_l3.png "Rendered by QuickLaTeX.com")
![\[= \mathop{\mathbb{E}[X_o^2] + 2M\mathop{\mathbb{E}[X_o] + \mathop{\mathbb{E}[M^2]\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-57b121875b129d8922f7689d19d3e38c_l3.png "Rendered by QuickLaTeX.com")
And since
![\mathop{\mathbb{E}[X_o] = 0](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-995b250f8a54065aeb18993d67af53b8_l3.png "Rendered by QuickLaTeX.com") and
and ![\mathop{\mathbb{E}[M^2] = M^2](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-1a5163c5268e58dfcdcd0820a762148d_l3.png "Rendered by QuickLaTeX.com") , we get:
, we get:
Which confirms the intuition. I know I skipped a few intermediate steps, but you should be able to fill those in. If you’re having any difficulties, let’s discuss this in the comment section below.
Alternative variance formula #2
Now let’s look at the second alternative variance formula I promised to show you.
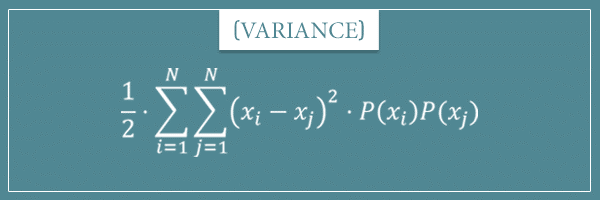
What’s interesting about it is that it makes no reference to the mean of the random variable! Let’s first look at its derivation and then we’ll discuss its interpretation as well.
Derivation
We can derive this alternative variance formula starting from the main formula, but I don’t want to interrupt our current journey. Since the last thing we did was derive the first alternative variance formula, let’s continue from there:
![\[\textrm{Variance(X)} = \mathop{\mathbb{E}[X^2] - \mathop{\mathbb{E}[X]^2\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-63030f4615e2c0e567a896659882293c_l3.png "Rendered by QuickLaTeX.com")
I first want to rewrite the two terms as double sums. The short answer to why I’m doing this is because I want to use equation (2) and join them back into a single sum. You’ll see the full reason shortly.
Rewriting the terms as double sums
Let’s start with the left term:
![\[\mathop{\mathbb{E}[X^2] = \sum_{i=1}^{N} x_i^2 \cdot p(x_i) = \sum_{i=1}^{N} x_i^2 \cdot p(x_i) \cdot 1\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-dd35563a6e890e5e16b943790d656e3c_l3.png "Rendered by QuickLaTeX.com")
All I did here is multiply the sum term by 1, which obviously doesn’t change its value. It looks a little silly, doesn’t it? Well, to see why I’m doing this, let’s rewrite the number 1 itself in the following way:
![\[1 = \sum_{j=1}^{N} p(x_j) \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-f612f8138f2655e7104b607086bcb977_l3.png "Rendered by QuickLaTeX.com")
We basically did the same thing in one of the steps in the previous section but in the opposite direction — the sum of all elements of a sample space is always equal to 1. Notice, however, that we’re using a different letter for the index — j instead of i. Now let’s replace the 1 inside the sum term with this sum:
![\[\mathop{\mathbb{E}[X^2] = \sum_{i=1}^{N} \left(x_i^2 \cdot p(x_i) \cdot \sum_{j=1}^{N} p(x_j) \right)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-9ee66d5a0d74d3336717d0d256199572_l3.png "Rendered by QuickLaTeX.com")
Because the
 part of the sum term is independent of j, it’s a constant with respect to the inner sum. Which means we can move it inside to obtain the following double sum:
part of the sum term is independent of j, it’s a constant with respect to the inner sum. Which means we can move it inside to obtain the following double sum: ![\[\mathop{\mathbb{E}[X^2] = \sum_{i=1}^{N} \sum_{j=1}^{N} x_i^2 \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-f23393729a40e652891bdb25a0552ab2_l3.png "Rendered by QuickLaTeX.com")
So far, so good! Now let’s also start writing the right term of the variance formula as a double sum:
![\[\mathop{\mathbb{E}[X]^2 = \left(\sum_{i=1}^{N} x_i \cdot p(x_i)\right)^2 = \sum_{i=1}^{N} x_i \cdot p(x_i) \cdot \sum_{j=1}^{N} x_j \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-abc21057a44acaaaad7ab6ab82215a70_l3.png "Rendered by QuickLaTeX.com")
All I did was write the second power more explicitly as a product. However, notice that again I used j as an index for the second sum! We can do that, right? Regardless of what letter you choose for the index, the sum remains the same. But now equation (3) (and the commutative property of multiplication) allows us to rewrite this product of sums as the following double sum:
![\[\sum_{i=1}^{N} x_i \cdot p(x_i) \cdot \sum_{j=1}^{N} x_j \cdot p(x_j) = \sum_{i=1}^{N} \sum_{j=1}^{N} x_i \cdot x_j \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-e53342cebfc33e9f52d9b1b457d4be63_l3.png "Rendered by QuickLaTeX.com")
Joining the terms into a single double sum
So far, we wrote the two terms of the variance formula as the following double sums:
![\[\mathop{\mathbb{E}[X]^2 = \sum_{i=1}^{N} \sum_{j=1}^{N} x_i \cdot x_j \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-78ca178230ce4f4dcfc3fca310ac2884_l3.png "Rendered by QuickLaTeX.com")
And when we plug these into the variance formula, we get:
![\[= \sum_{i=1}^{N} \sum_{j=1}^{N} x_i^2 \cdot p(x_i) \cdot p(x_j) - \sum_{i=1}^{N} \sum_{j=1}^{N} x_i \cdot x_j \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-853d43edbd6871cb67c4f59a642b5f59_l3.png "Rendered by QuickLaTeX.com")
But now, using equation (2), we can merge the two double sums into one:
![\[ \textrm{Variance(X)} = \sum_{i=1}^{N} \sum_{j=1}^{N} \left(x_i^2 \cdot p(x_i) \cdot p(x_j) - x_i \cdot x_j \cdot p(x_i) \cdot p(x_j)\right) \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-ab115669762aacc30530ca16d9aa448f_l3.png "Rendered by QuickLaTeX.com")
And using the distributive property of multiplication, we can factor out
 to finally obtain the formula:
to finally obtain the formula: ![\[\textrm{Variance(X)} = \sum_{i=1}^{N} \sum_{j=1}^{N} (x_i^2 - x_i \cdot x_j) \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-af71c7c572afdbad8aeecff8f9bfb68b_l3.png "Rendered by QuickLaTeX.com")
This is already an interesting expression! It tells us that the variance can also be written as this double sum whose terms are differences of the square of an element and the product of that element with another element.
But we’re not done yet. Let’s see if we can get this into an even more elegant shape.
Switching the indices
Notice that it was kind of arbitrary that we expressed the first index as i and the second as j. If we had started with j instead, an equally valid alternative representation of the formula above is:
![\[\textrm{Variance(X)} = \sum_{j=1}^{N} \sum_{i=1}^{N} (x_j^2 - x_j \cdot x_i) \cdot p(x_j) \cdot p(x_i)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-977ca164bfd96d8d1dc10ecd09b44a9a_l3.png "Rendered by QuickLaTeX.com")
But now, using equation (4), as well as the commutative property of multiplication, we can rewrite this as:
![\[\sum_{i=1}^{N} \sum_{j=1}^{N} (x_j^2 - x_i \cdot x_j) \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-a70597d63c83568a05aa8b120be96aa9_l3.png "Rendered by QuickLaTeX.com")
From which we conclude that this particular representation of the variance formula has a twin representation:
![\[\textrm{Variance(X)} =\sum_{i=1}^{N} \sum_{j=1}^{N} (x_i^2 - x_i \cdot x_j) \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-ab0e0d880b82787aa29d6f666a53d679_l3.png "Rendered by QuickLaTeX.com")
![\[= \sum_{i=1}^{N} \sum_{j=1}^{N} (x_j^2 - x_i \cdot x_j) \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-0d9b3bde2f4b63418960982933db3ab7_l3.png "Rendered by QuickLaTeX.com")
Keep these in mind because we’re going to use them in the final steps of the derivation.
The final steps
Now I want to apply another mathematical trick. I want to write an expression for twice the variance as addition:
![\[2\cdot \textrm{Variance(X)} = \textrm{Variance(X)} + \textrm{Variance(X)}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-cb808b460ee869bf1980916c66421756_l3.png "Rendered by QuickLaTeX.com")
However, for each
 term, I want to write a different version of the formula we derived above (the twin formulas):
term, I want to write a different version of the formula we derived above (the twin formulas): ![\[ 2\cdot \textrm{Variance(X)} = \sum_{i=1}^{N} \sum_{j=1}^{N} (x_i^2 - x_i \cdot x_j) \cdot p(x_i) \cdot p(x_j) + \sum_{i=1}^{N} \sum_{j=1}^{N} (x_j^2 - x_i \cdot x_j) \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-e1dd618b39f55813d32cf44f99beee5f_l3.png "Rendered by QuickLaTeX.com")
I’m doing this because now we can merge back the two sums. And after also factoring out the common terms, we get:
![\[2\cdot \textrm{Variance(X)} = \sum_{i=1}^{N} \sum_{j=1}^{N} (x_i^2 - 2 \cdot x_i \cdot x_j + x_j^2) \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-f76854edf32277bce05ba2343ae371a7_l3.png "Rendered by QuickLaTeX.com")
Now, do you notice anything familiar about the part inside the parentheses? It looks exactly like the right-hand side of equation (6), no? Using this equation, we can finally write the formula as:
![\[2\cdot \textrm{Variance(X)} = \sum_{i=1}^{N} \sum_{j=1}^{N} (x_i - x_j)^2 \cdot p(x_i) \cdot p(x_j) \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-c315db6cc7af1c3b9d5dd630135b8742_l3.png "Rendered by QuickLaTeX.com")

There you have it. Now all we need to do is divide both sides of this equation by 2 in order to get a formula for the variance that looks like this:
![\[\textrm{Variance(X)} = \frac{1}{2} \cdot \sum_{i=1}^{N} \sum_{j=1}^{N} (x_i - x_j)^2 \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-08ae97cf0a60aec0bdcdc21532ce9da8_l3.png "Rendered by QuickLaTeX.com")
Whoa! Look at this, it’s pretty isn’t it? We have expressed the variance of a random variable X in terms of the sum of the squared differences between all possible pairs of elements of its sample space. Not only that, this formula makes absolutely no reference to the mean of the distribution!
Discussion
Let’s do a quick recap. According to the original formula, the variance of a random variable X is equal to the expected value of the squared difference between X and its mean. And, according to the first alternative formula we derived, the same measure can be expressed as the difference between the expected value of the square of the variable and the square of its mean.
Now, after some additional manipulations, we found out that the exact same measure can also be expressed in terms of the square of differences between all possible values of X. Well, half of that, since we’re dividing the double sum by 2.
Apart from allowing us to calculate the variance without having to calculate the mean first, this formula offers additional insight about what the variance represents. Turns out, measuring dispersion through sums of squared differences from the mean is the same as summing all squared differences between the values themselves. The intuition behind dividing by two is that each pair of values is counted twice by the standard double sum, since:
![\[(x_i - x_j)^2 = (x_j - x_i)^2\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-ccda91efc7e5c90a3baacfafc0056db5_l3.png "Rendered by QuickLaTeX.com")
In other words, not dividing by two would overestimate the variance by a factor of 2. Although, notice that in principle
 is just as valid measure of dispersion as . Still, if you’re somewhat bothered by the
is just as valid measure of dispersion as . Still, if you’re somewhat bothered by the  factor, we can also write this formula as:
factor, we can also write this formula as: ![\[\textrm{Variance(X)} = \sum_{i=1}^{N} \sum_{j=i+1}^{N} (x_i - x_j)^2 \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-38b57e44003737010f1d22f02604a592_l3.png "Rendered by QuickLaTeX.com")
Here we removed the
factor but the index of the inner sum doesn’t start from 1. Instead, it starts from the current index of the outer sum + 1. If you remember, I talked about such expressions in a section of my post about the sum operator. Starting the inner sum’s index at i+1 instead of 1 leads to adding the square of differences between each pair only once and we no longer need the factor in front. Which probably makes the formula somewhat more elegant.
I’m going to revisit this formula in my post on measures of dispersion of categorical random variables (that is, ones with a categorical probability distribution). As you’ll see, this will offer further intuition about variance in general.
Now, before I conclude this post, I want to show you how all these alternative variance formulas translate to situations where, instead of a discrete distribution, we’re dealing with a continuous one or a finite population.
Generalizing alternative variance formulas
In my first and introductory post on variance, I gave you this formula for any finite collection of numbers:
Which, using equation (1), can be rewritten as:
![\[\textrm{Variance(X)} = \sum_{i=1}^{N} (M - x_i)^2 \cdot \frac{1}{N}\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-9bd97ca63c70ba428f64f875d40a61e5_l3.png "Rendered by QuickLaTeX.com")
Basically, the
 term is replaced by
term is replaced by  because each value in the collection has an equal chance of being selected.
because each value in the collection has an equal chance of being selected.
So, this is how the main variance formula translates from discrete probability distributions to finite populations. The two new variance formulas we derived today translate in the exact same way.
Finite populations
For discrete distributions, we derived:
![\[\textrm{Variance(X)} = \sum_{i=1}^{N} x_i^2 \cdot p(x_i) - \left(\sum_{i=1}^{N} x_i \cdot p(x_i)\right)^2\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-c3d87c8807da7e3381f29ffdaa8b0bfd_l3.png "Rendered by QuickLaTeX.com")
If we now replace the
and  terms with again, the finite population versions of these two formulas become:
terms with again, the finite population versions of these two formulas become: ![\[\textrm{Variance(X)} = \frac{1}{N} \cdot \sum_{i=1}^{N} x_i^2 - \frac{1}{N^2} \cdot \left(\sum_{i=1}^{N} x_i \right)^2\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-ba2385e90248766aad4b157cf8df9b06_l3.png "Rendered by QuickLaTeX.com")
![\[\textrm{Variance(X)} = \frac{1}{2N^2} \cdot \sum_{i=1}^{N} \sum_{j=1}^{N} (x_i - x_j)^2 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-e5c516ce1530ef07bc8f4d866c414678_l3.png "Rendered by QuickLaTeX.com")
Continuous distributions
Alright, what about continuous probability distributions? Remember the main variance formula for an arbitrary probability density function f(x):
To translate the first alternative formula, we simply need to calculate the expected value of the squares of X and subtract the square of the mean from it:
Which in the language of integrals translates to:
![\[\textrm{Variance(X)} = \int_{-\infty}^{\infty} x^2 \cdot f(x) \cdot \,dx - \left( \int_{-\infty}^{\infty} x \cdot f(x) \cdot \,dx \right)^2 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-48bf91dc6241e70ae28454f2c95ab0f9_l3.png "Rendered by QuickLaTeX.com")
The idea is that the sum operator turns into an integral where the
 term is replaced by the variable x multiplied by dx (since that’s the variable we’re integrating over). And, of course, the probability mass function is replaced with the probability density function
term is replaced by the variable x multiplied by dx (since that’s the variable we’re integrating over). And, of course, the probability mass function is replaced with the probability density function  .
.
For the second alternative variance formula, we replace the double sum with a double integral, as well as the and  terms with x and y:
terms with x and y:
![\[\textrm{Variance(X)} = \frac{1}{2} \cdot \int_{-\infty}^{+\infty} \int_{-\infty}^{+\infty} (x-y)^2 \cdot f(x) \cdot f(y) \cdot \,dx \cdot \,dy \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-ee03a4440fabcf0d75b1ed36174a0724_l3.png "Rendered by QuickLaTeX.com")
Since we’re integrating over x and y, for both we have the corresponding dx and dy terms. Finally, the
 product is replaced with
product is replaced with  .
.
For those of you not familiar with integrals, you’ll gain more intuition about the above formulas when I write my post dedicated to this topic. For now, I’m giving you these translations without a formal proof just so you have the big picture.
Summary
In today’s post I showed you two alternative variance formulas which are both useful and insightful. I derived these formulas for discrete probability distributions and later showed you their finite population and continuous distribution versions. Here’s a table that summarizes all these results:

I hope this post was also a useful exercise in manipulating expressions involving the sum operator. Some of the things we did weren’t exactly trivial but they are things you’ll come across in other mathematical texts quite often. If you understood everything in this post, this should boost your confidence in your ability to understand many other (even more advanced) derivations.
Overview of the derivation steps
Here’s a summary of the derivation steps of the first alternative formula:
![\[ \textrm{Variance(X)} = \sum_{i=1}^{N} (M - x_i)^2 \cdot P(x_i) = \sum_{i=1}^{N} (M^2 - 2Mx_i + x_i^2) \cdot P(x_i)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-3291ecd82d38f3e16653a2f20e9843d9_l3.png "Rendered by QuickLaTeX.com")
![\[ = M^2 \cdot \sum_{i=1}^{N} P(x_i) - 2M \cdot \sum_{i=1}^{N} x_i \cdot P(x_i) + \sum_{i=1}^{N} x_i^2 \cdot P(x_i) = M^2 - 2M^2 + \mathop{\mathbb{E}[X^2]\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-ae7ebbf2016bcb0862185a68215c975f_l3.png "Rendered by QuickLaTeX.com")
Finally:
![\[\textrm{Variance(X)} = \mathop{\mathbb{E}[X^2] - M^2 = \mathop{\mathbb{E}[X^2] - \mathop{\mathbb{E}[X]^2 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-72428d684f60b1bc53b5a2b51b4decbb_l3.png "Rendered by QuickLaTeX.com")
And here’s a summary of the steps for the second alternative variance formula:
In the beginning we simply wrote the terms of the first alternative formula as double sums. Then:
![\[\textrm{Variance(X)} = \sum_{i=1}^{N} \sum_{j=1}^{N} x_i^2 \cdot p(x_i) \cdot p(x_j) - \sum_{i=1}^{N} \sum_{j=1}^{N} x_i \cdot x_j \cdot p(x_i) \cdot p(x_j) \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-5b74dbc62be1ed59548b19a43e89c9c5_l3.png "Rendered by QuickLaTeX.com")
![\[= \sum_{i=1}^{N} \sum_{j=1}^{N} (x_i^2 - x_i \cdot x_j) \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-a2ad57eff7a8152116c27afbc6ffabb7_l3.png "Rendered by QuickLaTeX.com")
Finally, we multiplied the variance by 2 to get the following identity:
![\[2\cdot \textrm{Variance(X)} = \sum_{i=1}^{N} \sum_{j=1}^{N} (x_i^2 - x_i \cdot x_j) \cdot p(x_i) \cdot p(x_j) + \sum_{i=1}^{N} \sum_{j=1}^{N} (x_j^2 - x_i \cdot x_j) \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-84e42508c8f4a675d5ec9de3a7505cce_l3.png "Rendered by QuickLaTeX.com")
![\[ = \sum_{i=1}^{N} \sum_{j=1}^{N} (x_i^2 - 2 \cdot x_i \cdot x_j + x_j^2) \cdot p(x_i) \cdot p(x_j) = \sum_{i=1}^{N} \sum_{j=1}^{N} (x_i - x_j)^2 \cdot p(x_i) \cdot p(x_j)\]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-2e029f9a0ff098dcba268c31d2abbd40_l3.png "Rendered by QuickLaTeX.com")
And after dividing both sides of the equation by 2:
Well, I hope you learned something new (and useful) today. As always, if you got stuck somewhere or have any other questions (or insights of your own), feel free to drop a comment in the comment section below!
Very cool ! THX
This is an amazing post!
I am struggling with one part…in the equation after the following sentence in the “Alternative variance formula #1” section:
Which is simply the mean of the distribution from equation (5)!
I do not understand how the left side of the term equates to E[X^2]