 The inverse problem is fundamentally related to the subject of causality. Think about a scenario…
The inverse problem is fundamentally related to the subject of causality. Think about a scenario…
What will happen if you grab a solid rock and throw it at your neighbor’s window? The most common result is that the window will break. If your neighbor later asks if you know anything about the incident, you can confidently inform him that his window was broken because you threw a rock at it earlier. Cause and effect — sounds pretty straightforward.
But what if it wasn’t you who broke the window and, in fact, you have no idea what broke it? Did someone else throw a rock at it? Was there a large temperature difference between the center and the periphery of the glass which caused a spontaneous breakage? Or was it a spontaneous breakage caused by a fabric defect?
You see, unlike the previous question, this one is actually not straightforward to answer. It involves solving the sо-called inverse problem: inferring the causes of a particular effect.
In this post I’m going explain the inverse problem and give two examples of how it shows up in nature and science.
Bayes’ theorem is a powerful method for addressing the inverse problem in general. In the last section of the post, I’m going to demonstrate how to do this with a toy example. If you aren’t familiar with Bayes’ theorem, go ahead and check my introductory post.
Table of Contents
The forward and the inverse problems
In science, solving the forward problem means trying to predict the effects of a particular cause. Examples of questions that address the forward problem are:
- In which direction will a piece of magnet move if there is another piece of magnet next to it?
- How will the color of a litmus paper change if you put lemon juice on it?
- How will the structure of a glass window change after an impact with a rock of a particular mass and velocity?
Most of the time, the forward problem is well-posed.
In mathematics, a well-posed problem is one which has the following 3 properties (first suggested by the French mathematician Jacques Hadamard):
- The problem has a solution.
- The solution is unique.
- The solution is dependent and sensitive to the details of the problem.
The last property basically means that small changes in the details of the problem should only require small adjustments in its solution.
A problem which lacks either of these properties is called… ill-posed. You can see how trying to solve an ill-posed problem will generally make your life more difficult than solving well-posed problems.
To solve an inverse problem means inferring the causes of a particular effect. For example, if you see a moving magnet and want to find the cause of its movement (another magnet? strong wind?), you would be solving the inverse problem.
Most of the time, the inverse problem is ill-posed because it lacks the second of Hadamard’s properties. More than one cause can explain most effects. In fact, very often an infinite number of possible causes can explain an effect.
To summarize:
- The forward problem is predicting the effects of a particular cause. A forward problem is often well-posed.
- The inverse problem is finding the causes of a particular effect. Most of the time it’s ill-posed.
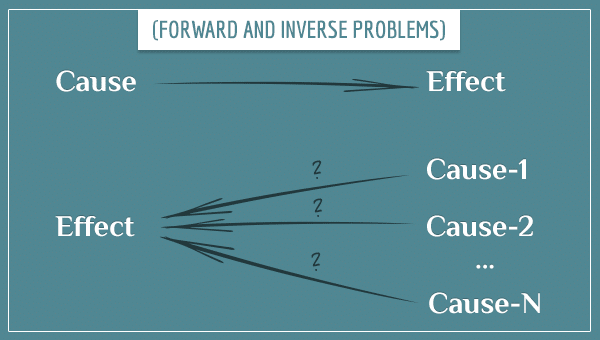
The fact that inverse problems are ill-posed doesn’t mean attempting to solve them is a hopeless effort. You can solve them indirectly (but not necessarily completely) with the help of additional information you use to narrow down the possible causes of an effect.
Inverse problem examples
In this section, I’m going to show two examples of where you can encounter the inverse problem.
Visual perception
When processing information, your brain is constantly trying to solve problems that fall in both forward and inverse categories. An example of the latter is visual perception. Think about how you perceive the correct size and distance of different objects in the environment, for example. You can’t do it directly because a small square 1 meter away from you will look exactly the same (will have the same retinal projection) as a larger square, say, 10 meters away from you.
Yes, they really look the same: your brain receives identical visual input for objects of different sizes, as long as they are at the right distance from your eyes (this follows from pure optics). This means that there is an infinite number of candidates for the right size and distance of any object.
How the brain solves the inverse problem
As I mentioned before, you can solve an inverse problem indirectly with the help of additional information. The brain actually uses two sources of such information:
- Prior information about the object. You brain has expectations for the typical sizes of many familiar objects, like cats, people, cars, trees, smartphones, and so on. These expectations come from past experience. So, after seeing an object, your brain assumes it has the typical size as other objects from the same category. Once the size of an object is fixed, inferring the distance becomes a well-posed problem and can be solved directly.
- Contextual information from the surroundings. If you’re looking at an unfamiliar object, your brain will make a guess about its size and distance using cues from the surrounding environment (like the size and distance of familiar objects around it). For example, if you see a person standing next to an unknown object, your brain will infer the size of the object by comparing it to the size of the person (for which it already has an estimate from past experience).
Most of the time, your brain uses both sources. When you look at the details, the process is actually much more complicated than I make it sound.
Funny things happen when these two sources give conflicting information. The Ames room is a famous example of an optical illusion caused precisely by your brain’s attempts to resolve such conflicts. Take a look at this 1-minute demonstration and explanation of the effect by the neuroscientist Vilayanur Ramachandran:
Most of the time the brain solves the inverse problem almost perfectly and almost immediately. However, as the example above shows, this is not always the case and you can trick a brain into solving the problem in a wrong way.
EEG recordings
The inverse problem also commonly appears in science when inferring the possible sources of particular measurements. An example of this is interpreting EEG measurements of brain activity.
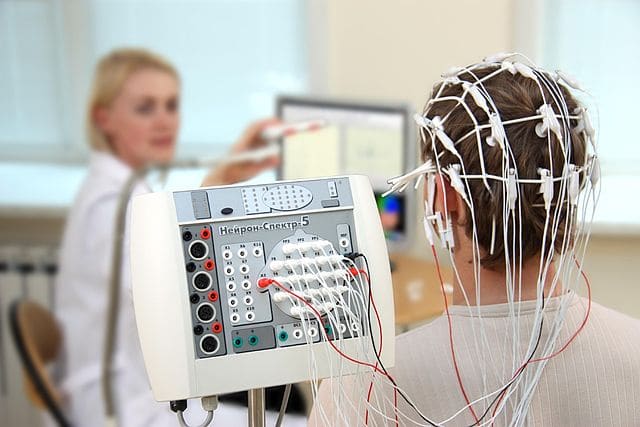
The white electrodes placed on the scalp are there to pick up the electric potentials generated by the activity of large groups of neurons in the brain. The goal is to use the recordings on the scalp to infer things about the underlying brain activity (like which regions are responsible for it).
This problem is very similar to the one in the visual perception example: there’s an infinite number of possible brain activity patterns that can produce the electric potentials recorded on the scalp. However, that doesn’t mean that all of these patterns are equally plausible. To infer the most likely brain sources of the recorded activity, scientists in the field have developed mathematical techniques that rely on certain implicit or explicit constraints (the “additional information” needed to address inverse problems).
Solving inverse problems using Bayes’ theorem
When you have many possible hypotheses for the causes of a particular effect, the problem of finding the correct one becomes probabilistic in nature. This makes Bayes’ theorem a perfect tool for solving an inverse problem.
What you have to do is collect evidence and apply Bayes’ theorem to update the probability of each hypothesis:

A job whose description is almost synonymous with “solving inverse problems” is that of a detective. The job requires investigating cases where there is an observed effect (usually a crime) of an unknown origin. To solve a case means to find its most likely origin. So, in this section, I’m going to show how you can use Bayes’ theorem for solving an inverse problem with a toy detective example.
A detective applying Bayes’ theorem to solve a case
Imagine that you’re a detective and you’re investigating a case of a gas station robbery. After interviewing a few witnesses, you’re certain about the following:
- The robber was wearing a brown t-shirt.
- He had a goatee.
- He escaped on a motorcycle.
Lucky for you, there are only 3 suspects:
- Jon
- Bob
- Tim
So, you build a hypothesis for each of them:
- Hypothesis-1: Jon robbed the bank.
- Hypothesis-2: Bob robbed the bank.
- Hypothesis-3: Tim robbed the bank.
For convenience, I’m going to label the three hypotheses simply “Jon”, “Bob”, and “Tim”.
Example probabilities
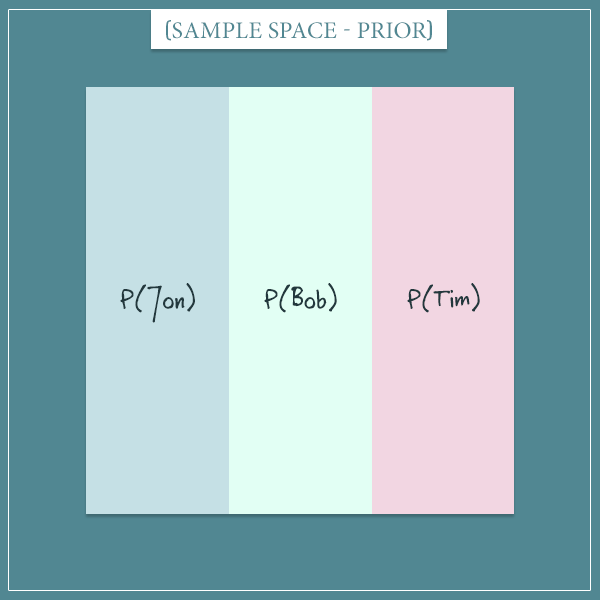
Because you initially don’t know anything about the suspects, you assign them equal prior probabilities:
![\[ P(\textrm{Jon}) = \frac{1}{3} \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-7dbfeabb5a2d521b0e73e97777e20d57_l3.png "Rendered by QuickLaTeX.com")
![\[ P(\textrm{Bob}) = \frac{1}{3} \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-61967fbd708b5e7787b5fc01626fad12_l3.png "Rendered by QuickLaTeX.com")
![\[ P(\textrm{Tim}) = \frac{1}{3} \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-cbeb1916a22c4581af3f163d488c83b1_l3.png "Rendered by QuickLaTeX.com")
Your goal is to use Bayes’ theorem to update those priors with the 3 pieces of evidence you collected from the witness interviews. In order to get the posterior probabilities, you need to know how the 3 hypotheses predict each piece of evidence. In other words, you need the values of the conditional probabilities:
- P(Goatee | Jon)
- P(Motorcycle |Tim)
- P(Brown t-shirt | Tim)
- Etc.
Normally, estimating a conditional probability like P(Goatee | Jon) is difficult. You would need to take into account information like:
- Whether Jon has a goatee now.
- If not, analyze his face to see if there are any recent shaving marks (in case he shaved after the day of the robbery to cover himself).
But, because this is a toy example, I can assign any values to those probabilities I want:

If the posterior probability term represents the solution of an inverse problem, the likelihood term represents the solution of a forward problem. It is the probability of observing the effect you are trying to explain if the hypothesis whose posterior probability you’re calculating is true. This is an important point because it shows the relationship between forward and inverse problems.
Alright, now all the information necessary for calculating the posterior probabilities is available. If you have any difficulties following the next steps, check my post Bayes’ Theorem: An Informal Derivation where I explained the mathematical theory and the intuition of Bayesian calculations.
Calculating the posterior probabilities
So, initially the sample space is uniform because each hypothesis has the same probability:
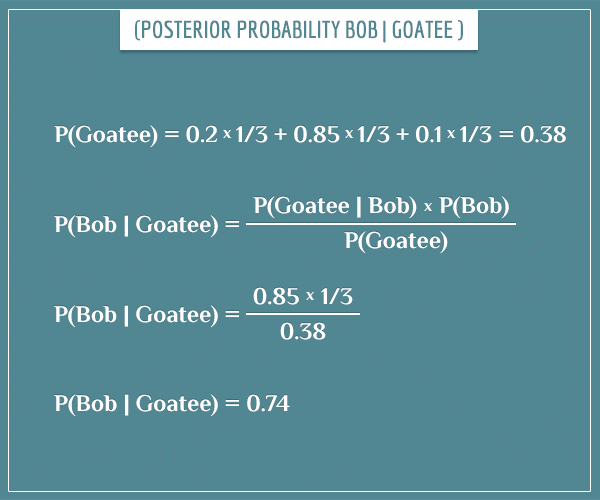
To calculate a posterior probability like P(Bob | Goatee), you need the values of the prior probability, likelihood, and evidence terms. The first two are already available and the evidence term is the sum of the prior probability*likelihood pairs for all hypotheses (capital G stands for “goatee”):
![\[ P(\textrm{G}) = P(\textrm{G} \mathbin{\vert} \textrm{Jon}) \cdot P(\textrm{Jon}) + P(\textrm{G} \mathbin{\vert} \textrm{Bob}) \cdot P(\textrm{Bob}) + P(\textrm{G} \mathbin{\vert} \textrm{Tim}) \cdot P(\textrm{Tim}) \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-4c071e20ef53c8ce78af71a7dbd3d223_l3.png "Rendered by QuickLaTeX.com")
Here’s the actual calculation of P(Bob | Goatee):
Applying this to the remaining two hypotheses gives you the following posterior probabilities:
![\[ P(\textrm{Jon} \mathbin{\vert} \textrm{Goatee}) = 0.17 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-7e28865a095c57be719904b6158f358b_l3.png "Rendered by QuickLaTeX.com")
![\[ P(\textrm{Bob} \mathbin{\vert} \textrm{Goatee}) = 0.74 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-78d687497c86e2c955ec57f5c536a305_l3.png "Rendered by QuickLaTeX.com")
![\[ P(\textrm{Tim} \mathbin{\vert} \textrm{Goatee}) = 0.09 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-716f392a22fc96caf5664abb91ecb1d7_l3.png "Rendered by QuickLaTeX.com")
And the new sample space is:

A big difference compared to the prior sample space! The reason the odds turned so much in favor of Bob is that the likelihood term P(Goatee | Bob) was much larger compared to that of the other suspects. Intuitively, the fact that there was a high probability that Bob had a goatee during the robbery increases the chance that Bob was the robber, given that you know the robber had a goatee.
Re-updating the new priors
Here’s the cool part: these posterior probabilities become the new prior probabilities which the next piece of evidence can update. For example, here’s how you calculate P(Bob | Motorcycle):

Here are the values of the new posterior probabilities:
![\[ P(\textrm{Jon} \mathbin{\vert} \textrm{Motorcycle}) = 0.16 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-6e8c53688c4e76b176be8a88305491f2_l3.png "Rendered by QuickLaTeX.com")
![\[ P(\textrm{Bob} \mathbin{\vert} \textrm{Motorcycle}) = 0.79 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-5b7cf77173fd8ebe168dc857e45db988_l3.png "Rendered by QuickLaTeX.com")
![\[ P(\textrm{Tim} \mathbin{\vert} \textrm{Motorcycle}) = 0.05 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-934433e84fdb89f1b556ed154991f683_l3.png "Rendered by QuickLaTeX.com")
Not a huge shift this time, although P(Bob) still increased at the expense of the other two hypotheses. Notice the prior probabilities P(Jon), P(Bob), and P(Tim) used in the calculation were no longer equal to 1/3, but to their respective posterior probabilities calculated in the previous step.
Applying the same procedure to the last piece of evidence yields the posterior probabilities:
![\[ P(\textrm{Jon} \mathbin{\vert} \textrm{Brown t-shirt}) = 0.19 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-d8cd8e94f5733b75ea9ad741e550fa91_l3.png "Rendered by QuickLaTeX.com")
![\[ P(\textrm{Bob} \mathbin{\vert} \textrm{Brown t-shirt}) = 0.76 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-29939ffdec7ace063f5a549410df44ed_l3.png "Rendered by QuickLaTeX.com")
![\[ P(\textrm{Tim} \mathbin{\vert} \textrm{Brown t-shirt}) = 0.05 \]](https://www.probabilisticworld.com/wp-content/ql-cache/quicklatex.com-e41d687a5d63cff8cb842573e87da936_l3.png "Rendered by QuickLaTeX.com")
And the final sample space looks like this:

The odds slightly shifted back to Jon, but Bob is still the big “favorite” for being the robber. This is a big increase from to the initial probability of 1/3 (while the other two suspects now seem unlikely robber candidates).
It’s important to point out that here I’m assuming the three pieces of evidence are independent from each other. That is, a conditional probability like P(Goatee | Motorcycle) is equal to P(Goatee).
If you would like to see how to calculate more complicated cases where this assumption doesn’t hold, check out my posts about Bayesian networks (part 1 and part 2) and compound event probabilities. On a related topic, you will likely also find my post on conditional dependence and independence very useful.
Summary
Every time you attempt to infer what caused an observed effect, you’re solving an inverse problem. You encounter inverse problems in physics, chemistry, geology, neuroscience, economics, and probably in every other scientific field in one form or another.
It’s difficult to solve inverse problems because they are often ill-posed and there are many (often infinitely many) possible causes of the very same effect.
Bayes’ theorem is a powerful method for addressing inverse problems by using evidence to update the probability of each possible cause.
Bayesian methods don’t automatically eliminate the difficulties of solving inverse problems. However, even though the solutions are probabilistic and not exact, it allows you to get arbitrarily close to an exact solution. You just have to continue collecting evidence and updating the probabilities of rival hypotheses.
Your explanation is just superb. Thank you for making the world more knowledgeable.
Hi, thank you for this post and for all others! They help me to realise what have been half-understood for years.
Have a question though. I can’t fully get, what is actually P(Goatee | Jon)? Is this the probability of that Jon was wearing a goatee at the moment when robbery happened?
And when you’re later calculating P (Goatee), how can this be interpreted? But we already know that the robber had a goatee, so shouldn’t it be equal to 1?
Or am I completely mixing things up?:) Thank you!
Hi, Valera!
Yes, you can read P(Goatee | Jon) as something like “the probability that the robber had a goatee, given that the robber was Jon”. Which is only true if Jon had a goatee at the day of the robbery. Intuitively, if we know that the robber had a goatee, then if we can also prove that Jon had a goatee at the day of the robbery, this would be evidence in favor of Jon being the robber. If he has a goatee now, then P(Goatee | Jon) = 1 (assuming “now” isn’t too far in time from the day of the robbery). But if he doesn’t have it now, then P(Goatee | Jon) is a number between 0 and 1, depending on the type of evidence that exists for him having recently shaved and things like that.
As for your other question, in a way P(Goatee) is the prior probability of the robber having had a goatee during the robbery. In this context, by “prior” I mean prior to the detective interviewing the witnesses and finding out the robber was wearing a goatee. Since we’re already assuming these are the only 3 suspects, P(Goatee) is the sum of the products of the form P(Goatee | X) * P(X), where X stands for the robber.
For more intuition about this calculation (and the evidence term in general), check out my post about the derivation of Bayes’ theorem.
Does this answer your questions?
By the way, the point I made about P(Goatee) being the probability prior to the actual observation that the robber had a goatee is very central to intuitively understanding what Bayes’ theorem does. More specifically, how it relates prior to posterior probabilities. If you’re still not sure you understand it completely, please don’t hesitate to ask more questions.
Hi, yes, I got the point now. And I had started to read your post about this theorem derivation just before received your reply on this:) Much clearer now, thank you!
Your posts are amazing! I wish I had found this a decade back 🙂
It makes statistics look so simple.
very nice explanation – please keep it up 🙂